
Blog / Afiliación
Web scraping en el marketing de afiliados - ¿como descargar una página web y adaptarla a tus necesidades?

Si alguna vez te has preguntado cómo descargar un sitio web completo, probablemente estés familiarizado con el término web scraping.
¿Qué es web scraping?
Web scraping significa descargar sitios web como copias a una computadora. Esta tecnología se utiliza no solo para descargar sitios web completos, sino también para extraer datos específicos de interés de un portal determinado. Todo el proceso se lleva a cabo mediante bots, un robot indexador o un script escrito en Python. Durante el scraping, se recopilan datos específicos y se copian de la red a la base de datos local.
Web scraping - ¿qué utiliza?
Ahora que sabes que es el web scraping probablemente puedas imaginarte cómo se puede usar.
El web scraping es un método clave para las empresas y los analistas que se esfuerzan por explorar y entender conjuntos de datos complejos de varias fuentes en internet. Este proceso te permite descargar automáticamente información de sitios web seleccionados y recopilarlos para un análisis detallado. Independientemente del tipo de datos - ya sean números, textos, imágenes u otro contenido - el web scraping permite agregarlos en un solo lugar, lo que permite una mejor comprensión de las tendencias, las relaciones y las dependencias.
Por ejemplo, las empresas pueden utilizar el web scraping para analizar las opiniones de los clientes de las revisiones de productos o servicios en varias plataformas, lo que te permite identificar patrones relacionados con el nivel de satisfacción del cliente y las áreas que necesitan mejoras. A su vez, las empresas de análisis de mercado pueden recopilar datos sobre los precios de los productos y servicios, el volumen de ventas y las tendencias del consumidor, lo que apoya las estrategias de precios y la planificación de las actividades de marketing.
Gracias al web scraping los analistas también pueden realizar investigaciones sobre el comportamiento de los usuarios en los sitios web, analizando, entre otros, la navegación, las interacciones y el tiempo dedicado a las páginas individuales. Esto, a su vez, puede ayudar a optimizar la interfaz de usuario, mejorar la experiencia del usuario e identificar áreas que necesitan más mejoras.
En medicina e investigación científica, el web scraping se puede utilizar para recopilar datos de publicaciones científicas, ensayos clínicos o sitios web médicos, lo que te permite analizar las tendencias de salud, estudiar la eficacia de las terapias o identificar nuevos descubrimientos.
En resumen, el web scraping como herramienta de recopilación de datos para el análisis abre la puerta a una comprensión más profunda de los fenómenos, las relaciones y las tendencias en diversos campos. Sin embargo, es importante recordar los aspectos éticos y legales del web scraping tanto como tener cuidado y seguir las normas que rigen el acceso a los datos públicos y privados.
Web scraping en el marketing de afiliados
¿Cómo el scraping está familiarizado con el marketing de afiliados? Comencemos con el argumento más importante que lo impulsa a interesarse en el web scraping, es decir, el tiempo ahorrado, que gana al descargar sitios web de la competencia. Todo el mundo sabe, o al menos supone, que el proceso de creación de una buena landing page puede llevar mucho tiempo y que el éxito depende, entre otras cosas, del tiempo. Otros factores son la apertura al cambio de enfoque, la búsqueda de nuevas campañas, la realización de pruebas y, por supuesto, el análisis publicitario. El éxito lo logran aquellos que no se detienen en nimiedades, sino que buscan formas de escalar. Para ejecutar una campaña, debe investigar mucho sobre el grupo objetivo, la selección de GEO, las ofertas, etc., así como preparar los consumibles, incluida una landing page.
Algunas personas prefieren usar las páginas de destino proporcionadas por la red de afiliados, otras usan plantillas listas para usar de los creadores de páginas y otras prefieren crear una página de destino desde cero. Las dos primeras opciones son las más comunes. En algunos casos, pueden volverse rentables, pero esta no es una solución a largo plazo, ya que la competencia es feroz y los paquetes con plantillas disponibles se agotan rápidamente.
Una página de destino de alta calidad es la clave del éxito futuro y un buen retorno de la inversión. Vale la pena agregar que no todas las páginas de destino de un competidor pueden brindar el resultado esperado. Es mejor afinar la landing page deseada, teniendo en cuenta los criterios de la futura campaña publicitaria.
Por supuesto, debe recordar hacer todo legalmente, es decir. De acuerdo con ciertas reglas, que aprenderás en un momento.
¿Es el web scraping legal?
Sí. El web scraping no es una tecnología prohibida y las empresas que lo utilizan lo hacen de acuerdo con la ley. Desafortunadamente, siempre habrá alguien que comience a usar una herramienta determinada para actividades de piratería. El web scraping se puede utilizar para perseguir precios injustos y robar contenido protegido por derechos de autor. Está claro que el propietario de un sitio web que está bajo el web scraping puede sufrir enormes pérdidas financieras. Curiosamente, varias empresas extranjeras utilizaron el web scraping para guardar historias de Instagram y Facebook que deberían tener un límite de tiempo.
Scraping está bien siempre y cuando respetes los derechos de autor y cumplas con los estándares establecidos. Si decides cambiar al lado más oscuro que no se acepta en MyLead, puedes enfrentar varias consecuencias.
Algunas buenas prácticas al realizar scraping de sitios web
Recuerda sobre el GDPR
Cuando se trata de países de la UE, debes cumplir con el reglamento de protección de datos de la UE, comúnmente conocido como GDPR. Si no estás borrando datos personales, no necesitas preocuparte demasiado por eso. Te recordamos que dato personal es cualquier dato que pueda identificar a una persona, por ejemplo:
- nombre y apellido,
- email,
- número de teléfono,
- dirección,
- nombre de usuario (e.g. login / nickname),
- IP address,
- información del número de una tarjeta de crédito o débito,
- datos médicos o biométricos.
Para poder realizar scraping necesitas razones para almacenar la información personal. Ejemplos de tales razones son:
1. Interés legítimo
Debe probarse que el procesamiento de datos es necesario para los fines del negocio legítimo. Sin embargo, esto no se aplica a situaciones en las que estos intereses sean anulados por los intereses o los derechos y libertades fundamentales de la persona cuyos datos desea procesar.
2. Consentimiento del cliente
Cada persona cuyos datos desee recopilar debe dar su consentimiento para la recopilación, el almacenamiento y el uso de sus datos en la forma en que pretende hacerlo, p. con fines de mercadeo.
Si no tienes el consentimiento ni la aceptación del cliente, si no tienes un interés legítimo o el consentimiento del cliente, estás violando el RGPD, lo que puede resultar en una multa, restricción de libertad o prisión de hasta dos años.
¡Atención!
GDPR aplica a los residentes de los países de la Unión Europea, aplica a los países como Estados Unidos, Japón o Afghanistan.
Cumplir con los derechos de autor
Los derechos de autor son el derecho exclusivo de cualquier trabajo realizado, por ejemplo, un artículo, una foto, un video, una pieza musical, etc. Puede adivinar que los derechos de autor son muy importantes en el web scraping, porque muchos datos en Internet están protegidos por derechos de autor. Por supuesto, existen excepciones en las que puedes utilizar web scraping y usar datos legalmente sin infringir las leyes de derechos de autor, y estas son:
- utilización para uso público personal,
- utilización con fines didácticos o para actividades científicas,
- utilización bajo el derecho de cotización.
Web scraping - ¿dónde comenzar?
1. URL
El primer paso es encontrar la URL de la página que le interesa. Especifica el tema que deseas elegir. Solo está limitado por tu imaginación y fuentes de datos.
2. HTML code
Aprende la estructura del código HTML. Sin conocer HTML, tendrás dificultades para encontrar un elemento que descargue del sitio web de tus competidores. La mejor manera es ir al elemento en el navegador y usar la opción Inspeccionar. Luego verás las etiquetas HTML y podrás identificar el elemento de interés. Aquí está el ejemplo de esto en Wikipedia:
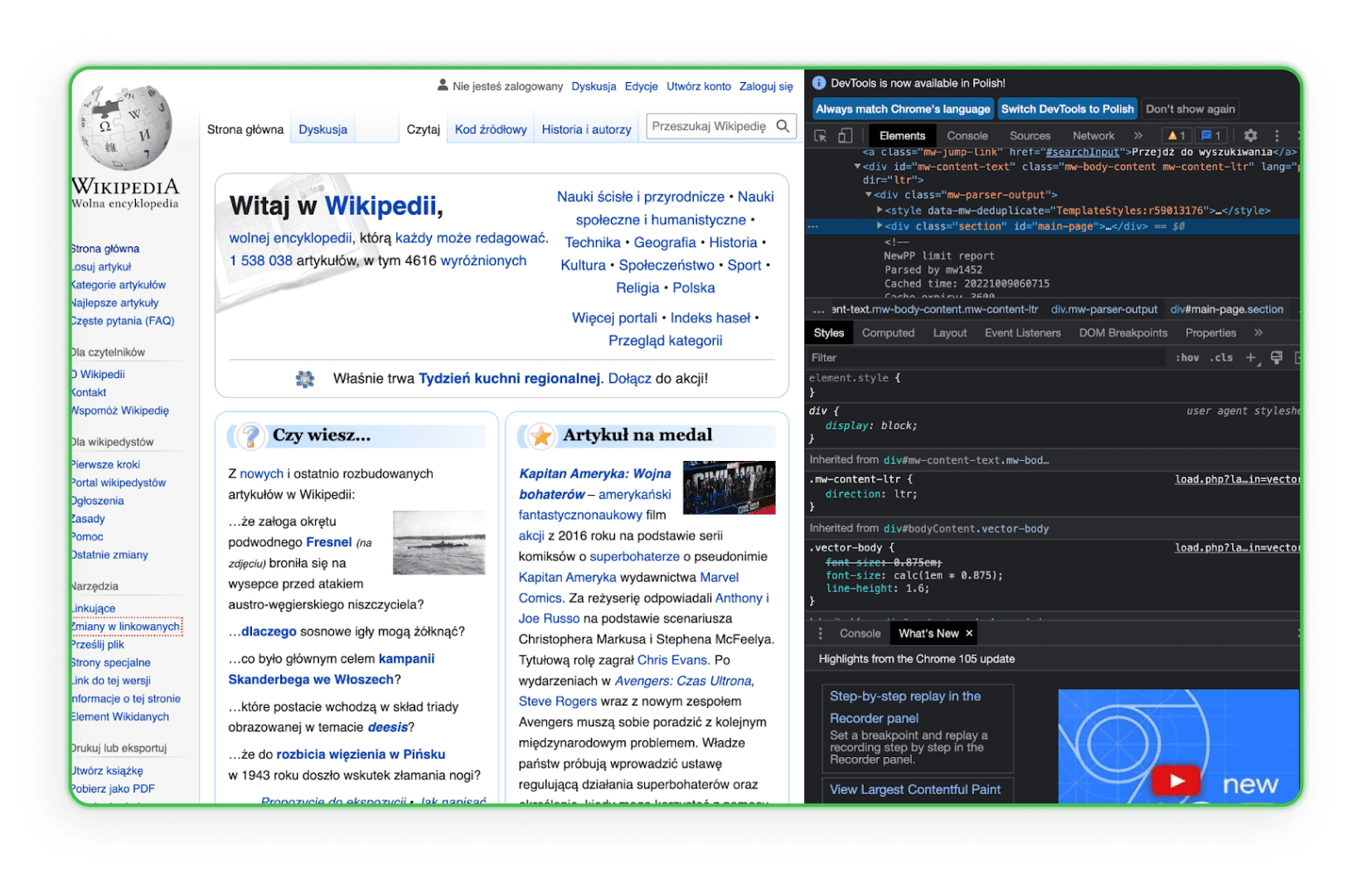
Como puedes observar, cuando mueves el mouse sobre una línea de códigos, el elemento correspondiente a la línea de código será resaltado en la página.
3. Entorno de trabajo
Tu entorno de trabajo debe estar listo. Más tarde descubrirás que necesitarás editores de texto como Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS) o Sublime Text, así que consiga uno ahora.
Biblioteca para el webscraping, es decir, ¿cómo guardar una página web?
Las bibliotecas de Webscraping son conjuntos organizados de scripts y funciones escritas en lenguajes de programación específicos que ayudan en la descarga automática de los datos de los sitios web. Permiten a los desarrolladores analizar, filtrar y extraer fácilmente contenido de páginas web HTML o XML. Gracias a ellos, en lugar de escribir cada función manualmente, los desarrolladores pueden utilizar soluciones listas para usar y optimizadas para buscar, navegar y manipular la estructura de los sitios web.
Simple HTML DOM Parser - biblioteca en PHP
Es una herramienta para los programadores PHP, que permite manipular e interactuar con el código HTML. Esto permite buscar, analizar o extraer fragmentos específicos de código HTML de una manera fácil e intuitiva.
Beautiful Soup - biblioteca en Python
Beautiful Soup es una biblioteca de Python utilizada para analizar documentos HTML y XML. Ha sido diseñada de tal manera que permite navegar, buscar y modificar fácilmente el árbol DOM, a la vez que proporciona interfaces intuitivas para extraer datos de las páginas.
Scrapy - biblioteca en Python
Scrapy es una poderosa biblioteca y framework para el despiece web en Python. Permite crear robots especiales que pueden buscar páginas, seguir enlaces, extraer la información que necesita y guardarlos en los formatos deseados. Scrapy es ideal para aplicaciones más complejas donde se requiere una búsqueda profunda o interacción con formularios y otros elementos de la página.
Guardar las páginas a través del navegador
Al ingresar a cualquier navegador, cualquier persona, incluido tú, puedes guardar la página seleccionada en tu ordenador, solo dedícale unos minutos de su tiempo. Una página duplicada se guarda en la computadora del usuario como un archivo y una carpeta HTML. La copia completa de la página se abre en el navegador y se ve bastante fluida. Sin embargo, para guardar una página realmente grande, este proceso deberá repetirse muchas veces.
Si deseas ahorrar tiempo y reducir la molestia de hacer una copia de seguridad de tu sitio, puedes obtener ayuda de terceros pagados. Hay muchas empresas y autónomos en Internet que harán todo por ti a cambio de una tarifa. Uno de los servicios de copia de sitios web es ProWebScraper. Tienen disponible una versión de prueba con la que puedes descargar 100 páginas. Después, claro, llegará el momento de pagar, que es desde 40 dólares al mes, dependiendo de cuántas páginas quieras scrapear . Siempre puedes encontrar otro sitio con un período de prueba gratuito. Vale la pena mencionar que algunos portales te permiten verificar si una página determinada es copiable, porque muchos sitios web están protegidos contra eso.
Otras herramientas más amigables para los usuarios principiantes
No todo el mundo que quiere hacer webscraping es un programador experimentado. Para aquellos que buscan soluciones menos técnicas, y más intuitivas, hay herramientas diseñadas específicamente para tener un uso simple. Gracias a la interfaz visual y el mecanismo de funcionamiento sencillo, los siguientes programas permiten recopilar datos de forma efectiva desde sitios web sin tener que escribir un código.
ZennoPoster
ZennoPoster es una herramienta de automatización y webscraping, que está más dirigida a las personas que no son necesariamente expertos en programación. Gracias a la interfaz visual de usuario, le permite crear scripts para el webscraping y otras funciones automatizadas en su navegador.
Costo: El costo de la herramienta es de $37 mensual, pero dispone de un periodo de prueba gratuita de 14 días.
Browser Automation Studio
BAS es otro programa fácil de usar para la automatización del navegador y el webscraping. Dispone de una herramienta completa para la creación de scripts, que permite extraer datos, navegar por páginas y muchas otras funciones sin necesidad de saber sobre programación.
Costo: Esta herramienta es gratuita.
Octoparse
Octoparse esta aplicación del web scraping, que permite recopilar grandes cantidades de datos de sitios web fácilmente. Gracias a la interfaz visual, los usuarios pueden definir qué datos se deben recopilar, y Octoparse se ocupa del resto.
Costo: A pesar de que hay una versión de esta herramienta disponible gratis, esta tiene ciertas limitaciones. En la versión gratuita, los usuarios pueden almacenar hasta 10 tareas en tu cuenta, y todas las tareas solo se pueden ejecutar en dispositivos locales utilizando tu propia dirección IP. La exportación de datos bajo el plan gratuito está limitada a 10.000 líneas para cada exportación, aunque la herramienta te permite buscar un número ilimitado de páginas en un solo inicio. También se pueden usar en cualquier número de dispositivos. Sin embargo, el soporte técnico en esta versión es limitado. La versión paga comienza desde $75 por mes.
import.io
import.io es una nube basada en una herramienta de webscraping que te permite crear y ejecutar scripts para extraer datos de sitios web. También tiene funciones que estructuran automáticamente los datos recopilados y los transforman en formatos útiles como Excel o JSON.
Costo: La herramienta ofrece un demo gratuito; sin embargo, los paquetes pagos comienzan desde $399 por mes.
Servicios para el web scraping en línea
El web scraping en línea funciona como analizadores (analizadores de componentes), pero su principal ventaja es la capacidad de trabajar en línea sin descargar e instalar el programa en tu ordenador. El principio de funcionamiento de los sitios web que ofrecen web scraping en línea es bastante simple. Ingresamos la URL de la página que nos interesa, establecemos las configuraciones necesarias (puede copiar la versión móvil de la página y cambiar el nombre de todos los archivos, el programa guarda HTML, CSS, JavaScript, fuentes) y descargamos el archivo. Con este servicio, el webmaster puede guardar cualquier página de destino y luego ingresar su propio formato y las correcciones necesarias.
Guarda una Web 2 ZIP

Save a Web 2 ZIP es el sitio web más popular cuando se trata de web scraping a través de un servicio de navegador. Un diseño muy simple y bien pensado atrae e inspira confianza, y todo es completamente gratis. Todo lo que necesita hacer es proporcionar el enlace de la página que desea copiar, elegir las opciones que deseas y está listo.
LPcopier
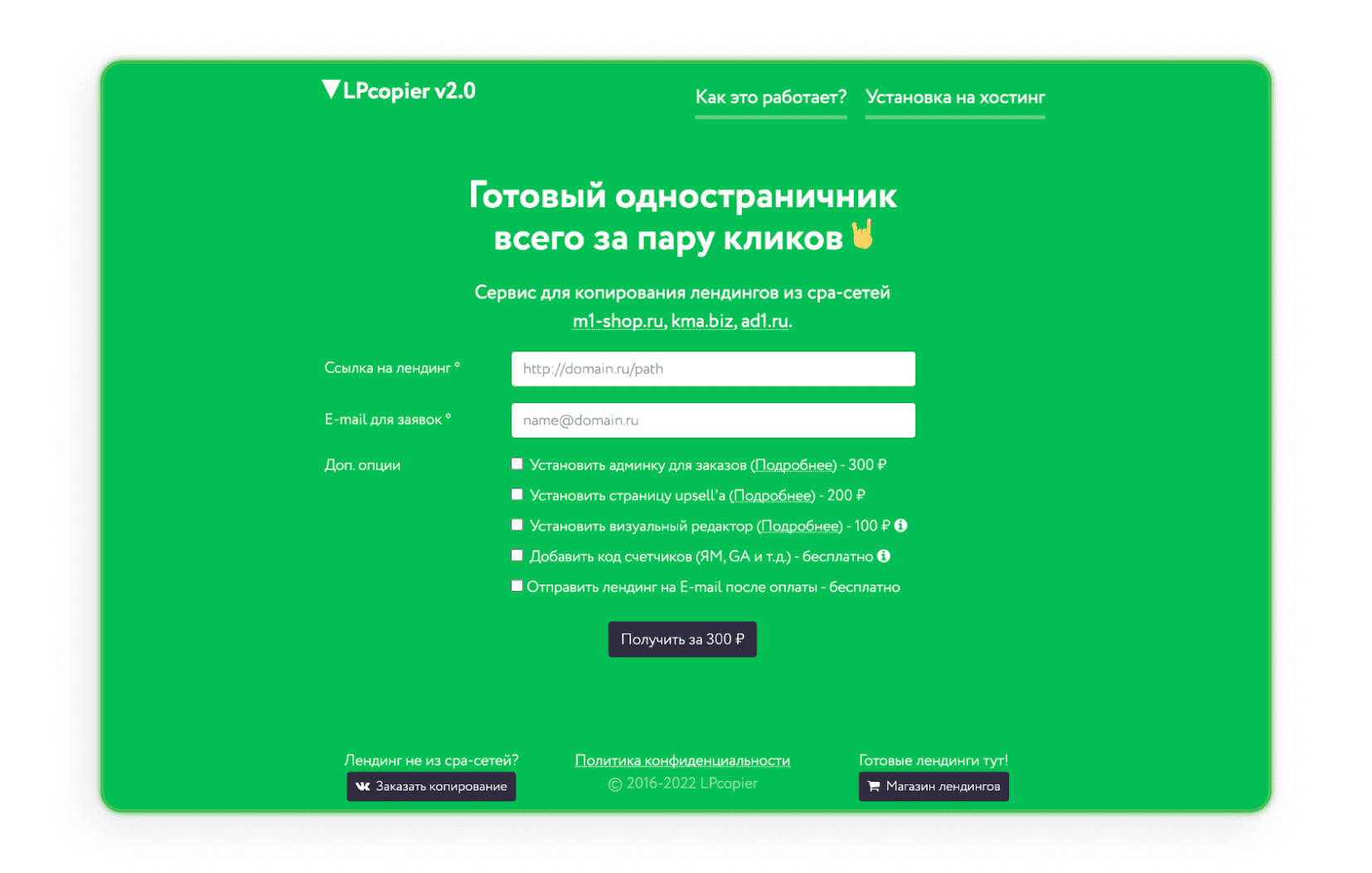
LPcopier es un servicio ruso que está dirigido al mundo del marketing de afiliados. El portal permite realizar web scraping desde unos 5 dólares por página. Los servicios adicionales, como la instalación de medidores analíticos, se consideran por separado en términos de costo. También es posible solicitar una página de destino que no sea de la red CPA o de una página de destino ya lista. Si el idioma ruso te asusta, solo usa la opción de traducción que ofrece Google.
Xdan
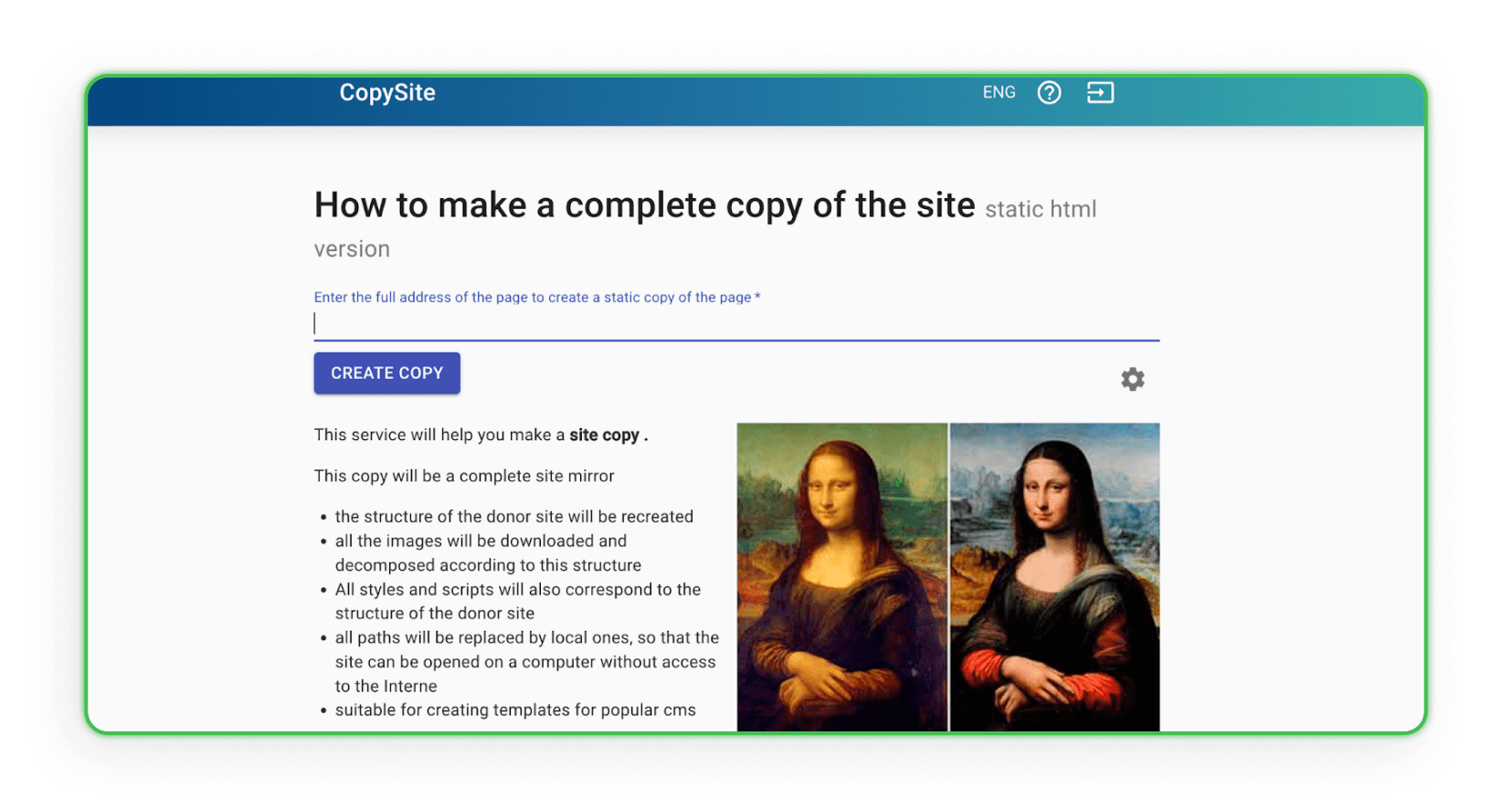
El sitio web de Xdan también es un sitio web ruso (disponible en inglés) que ofrece CopySite, es decir, servicios de web scraping. Con la ayuda de este sitio web, puedes crear una copia local de una página de destino de forma gratuita con la opción de limpiar contadores HTML, reemplazar enlaces o dominios.
Copysta

El servicio ruso llamado Copyst es uno de los servicios más rápidos de este tipo. Declaran que se pondrán en contacto contigo en 15 minutos. El web scraping en sí se realiza a través de un enlace y, por una tarifa adicional, puedes actualizar el sitio web.
He descargado la página web. ¿Qué sigue?
¿Ya has descargado una página web? Genial, ahora tienes que pensar que harás con esta. Seguramente deberás modificarla un poco. ¿Verdad?
¿Cómo rediseñar una página copiada?
Para rediseñar la página copiada según tus propias necesidades, debes duplicar el activo como desees. Para realizar cambios en la estructura, puedes usar cualquier editor que te permita trabajar con el código, como Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS) o Sublime Text. Abre un editor que sea conveniente para ti, personaliza el código, luego guárdalo y prueba cómo se muestran los cambios en el navegador. Edita la apariencia visual de las etiquetas HTML mediante el uso de CSS, agrega los formularios web, botones de acción, enlaces, etc. Después de guardar, el archivo modificado permanecerá en la computadora con funciones actualizadas, diseño y acciones dirigidas.
También hay sitios web que recopilan y analizan todos los datos de diseño de archivos web específicos que tienen un sistema de gestión y creación de sitios web (CMS). El sistema crea un duplicado del proyecto con el administrador y el espacio en disco. Archivarix es un ejemplo de un sitio web de este tipo (el programa puede restaurar y archivar el proyecto).
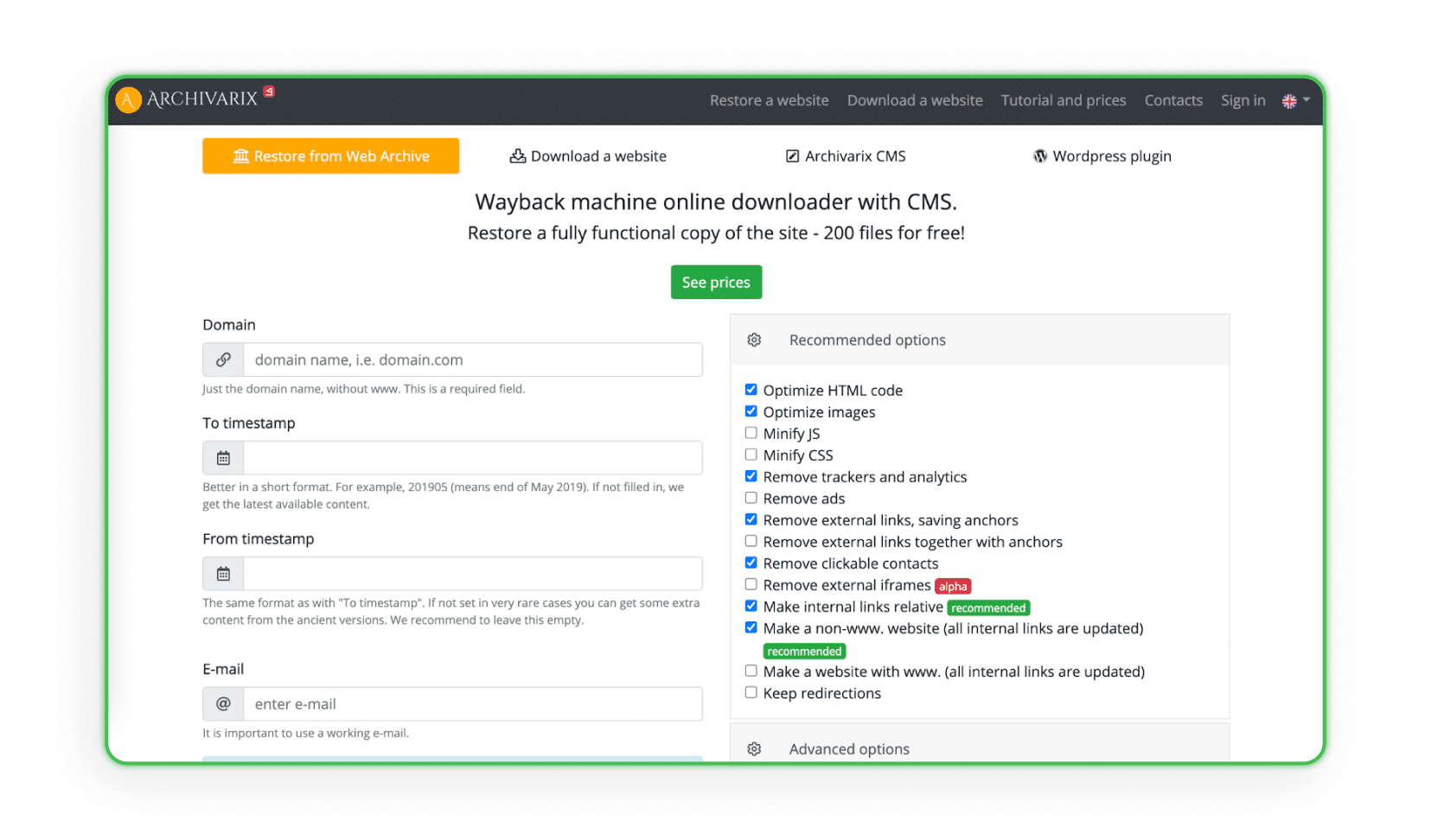
Sube el sitio web al hosting
El último y más importante paso en el web scraping de páginas de destino es subirlas a su alojamiento. Recuerda que copiando y haciendo pequeños cambios visuales no es suficiente. Los enlaces de afiliados, scripts, píxeles de reemplazo, códigos JS Metrica y otros contadores de otras personas casi siempre permanecen en el código de la página. Deben eliminarse manualmente (o con programas pagos) antes de cargarlos en tu hosting. Si quieres saber exactamente cómo subir tu sitio web a hosting, consulta nuestro artículo: “¿Cómo crear una landing page? Creando un sitio web paso a paso”.
¿Cómo protegerte antes el web scraping?
Protegerte antes el web scraping es esencial para mantener la privacidad y seguridad de tu sitio web y sus datos. Hay diferentes métodos a los que puedes aplicar para minimizar el riesgo de recibir un ataque de web scraping.
- Robots.txt - Utilizando el archivo robots.txt de la manera estándar para comunicar con los robots de búsquedas. El uso del archivo robots.txt es una forma estándar de comunicarse con los robots de búsqueda. Puedes especificar qué partes de tu sitio pueden buscarse y cuáles no. Aunque los robots honestos suelen seguir estas pautas, vale la pena señalar que este archivo no garantiza la protección contra todos los robots de web scraping.
- .htaccess - A través del archivo .htaccess, puedes bloquear el acceso de agentes de usuario específicos que pueden ser utilizados por los bots. Es una manera de rechazar bots no deseados de acceder a su sitio web.
- CSRF (Cross-Site Request Forgery) - El mecanismo de CSRF se puede utilizar para asegurar formas e interacciones con su sitio contra el web scraping automático. Esto podría implicar el uso de tokens CSRF en formularios.
- IP Address Filtering - Puedes limitar el acceso a tu sitio web solo para ciertas direcciones IP, lo que puede ayudar a minimizar los ataques web scraping.
- CAPTCHA - Agregar CAPTCHA a formularios e interacciones puede hacer que sea difícil para los bots interactuar con su sitio automáticamente. Es una de las defensas más populares contra el raspado automático.
- Rate Limiting with mod_qos on Apache servers - al establecer límites para el número de solicitudes de una sola dirección IP dentro de un plazo especificado puede limitar la posibilidad de descargas automáticas de grandes cantidades de datos en un corto tiempo.
- Scrapshield - El servicio de scrapshield ofrecido por CloudFlare es una herramienta avanzada para detectar y bloquear las actividades de web scraping, la cual puede asistir en protección a tu sitio.
Y si alguna vez notaste que tu landing page fue víctima de la técnica web scraping, también hay una manera de obtener algo del tráfico de vuelta a tu sitio.
En el foro Afflift, encontrarás un código simple de JavaScript. Colócalo en tu sitio, y te protegerá de la perdida total de tráfico en el caso de un web scraping.
Puedes encontrar el código en este HILO DEL FORO.
¡Qué bueno es verte aquí!
Esperamos que ahora sepas qué es el web scraping, cómo descargar un sitio web y, sobre todo, cómo respetar los derechos de autor. Ahora es tu turno de dar el primer paso y comenzar a ganar dinero. De todas maneras, si tienes alguna preguntas sobre el marketing de afiliados o no sabes que programa seleccionar, por favor contáctanos.
¿Tienes alguna pregunta? No dudes en contactarnos a través de nuestros canales.