
Blog / Afiliacja
Web scraping w afiliacji — jak pobrać i przerobić stronę WWW?
Web scraping to proces automatycznego pobierania danych ze stron internetowych za pomocą botów, skryptów w Pythonie lub gotowych narzędzi. W marketingu afiliacyjnym pozwala szybko kopiować i analizować landing page konkurencji, oszczędzając godziny pracy nad własną kampanią. Pobrane dane trafiają do lokalnej bazy, którą wydawca dostosowuje do własnych ofert i GEO.
Z tego poradnika dowiesz się, jak legalnie scrapować strony, jakich narzędzi i bibliotek użyć oraz jak przerobić skopiowany landing page pod własną kampanię afiliacyjną.
Z tego artykułu dowiesz się:
czym jest web scraping i jak działa pobieranie stron,
do czego wykorzystuje się scrapowanie w biznesie i afiliacji,
czy web scraping jest legalny w świetle RODO i praw autorskich,
jakich narzędzi, bibliotek i usług online użyć do kopiowania stron,
jak przerobić pobrany landing page i bezpiecznie wgrać go na hosting.

Co to jest web scraping i jak działa?
Web scraping to automatyczne pobieranie danych ze stron internetowych za pomocą botów, robotów indeksujących lub skryptów napisanych w Pythonie. Proces polega na wczytaniu kodu HTML strony, odfiltrowaniu wskazanych elementów i zapisaniu ich w lokalnej bazie danych, arkuszu lub pliku. Scraper pobiera kod źródłowy tak samo jak przeglądarka, ale zamiast go wyświetlać — ekstrahuje dane.
Scraper pobiera dowolne treści — liczby, teksty, obrazy — i porządkuje je w jednym miejscu, co ułatwia analizę trendów i zależności. Jeśli pojęcia branżowe są dla Ciebie nowe, sięgnij po słownik marketingu afiliacyjnego, w którym znajdziesz ponad 100 terminów wydawcy.
Do czego wykorzystuje się web scraping?
Web scraping wykorzystuje się głównie do gromadzenia i porównywania danych z wielu źródeł internetowych. Firmy i analitycy stosują go do monitoringu cen konkurencji, analizy opinii klientów, badania trendów konsumenckich oraz zachowań użytkowników na stronach. W nauce i medycynie scraping zbiera dane z publikacji i badań klinicznych, wspierając analizę skuteczności terapii.
Monitoring cen — śledzenie cen produktów, wolumenu sprzedaży i trendów konsumenckich konkurencji.
Analiza opinii — zbieranie recenzji z wielu platform w celu oceny zadowolenia klientów.
Badania użytkowników — analiza nawigacji, interakcji i czasu spędzonego na stronie w celu optymalizacji UX.
Nauka i medycyna — agregacja danych z publikacji naukowych, badań klinicznych i witryn medycznych.
Jak web scraping pomaga w marketingu afiliacyjnym?
W marketingu afiliacyjnym web scraping pozwala pobrać i przeanalizować landing page konkurencji, oszczędzając godziny pracy nad własną kampanią. Stworzenie skutecznej strony docelowej od zera jest czasochłonne, a sukces wydawcy zależy od tempa testowania ofert, GEO i grup docelowych. Skopiowany szablon przyspiesza start, lecz wymaga dopracowania pod własne potrzeby.
Wysokiej jakości strona docelowa jest kluczem do dobrego zwrotu z inwestycji. Masz trzy opcje: gotowe landingi z sieci afiliacyjnej, szablony z kreatorów lub własną stronę od zera. Skopiowany landing dopracuj pod kryteria swojej kampanii, korzystając z zasad tworzenia dobrego landing page'a.
Jeśli wolisz zbudować stronę samodzielnie, sprawdź przewodnik jak stworzyć landing page krok po kroku. Dołącz do MyLead i wykorzystaj zaoszczędzony czas na testowanie kolejnych kampanii afiliacyjnych.
Czy web scraping jest legalny?
Tak — web scraping jest legalny, a firmy korzystają z niego zgodnie z prawem. Sama technologia nie jest zakazana, problem pojawia się przy łamaniu praw autorskich, kradzieży treści lub nieuczciwej polityce cenowej. Scrapowanie pozostaje w porządku, dopóki przestrzegasz praw autorskich i wyznaczonych standardów, w tym zasad obowiązujących w MyLead.
Scraping bywa wykorzystywany do działań pirackich — kradzieży treści chronionych prawem autorskim lub nieuczciwej polityki cenowej, co naraża właściciela atakowanej strony na realne straty finansowe. Jeśli przejdziesz na ciemniejszą stronę, nieakceptowaną w MyLead, liczysz się z konsekwencjami.
Jakich zasad przestrzegać podczas scrapowania stron?
Podczas scrapowania stron WWW musisz przestrzegać dwóch kluczowych zasad: ochrony danych osobowych (RODO) oraz praw autorskich. RODO obowiązuje wyłącznie w krajach Unii Europejskiej i dotyczy danych identyfikujących osobę. Prawa autorskie chronią dzieła takie jak artykuły, zdjęcia czy filmy — większość treści w internecie jest nimi objęta.
Pamiętaj o RODO
RODO to unijne rozporządzenie o ochronie danych osobowych — jeśli nie scrapujesz danych identyfikujących osobę, nie musisz się nim przejmować. Aby legalnie przetwarzać dane osobowe, potrzebujesz podstawy prawnej: uzasadnionego interesu lub zgody klienta. Naruszenie RODO grozi grzywną, a nawet karą ograniczenia lub pozbawienia wolności do dwóch lat.
Dane osobowe to wszelkie informacje, które mogą zidentyfikować osobę:
imię i nazwisko,
adres e-mail,
numer telefonu,
adres zamieszkania,
nazwa użytkownika (login lub nick),
adres IP,
numer karty kredytowej lub debetowej,
dane medyczne lub biometryczne.
Aby przetwarzać dane osobowe, potrzebujesz jednej z podstaw prawnych:
Uzasadniony interes — musisz udowodnić, że przetwarzanie jest niezbędne do celów wynikających z prawnie uzasadnionego interesu i nie narusza praw osoby.
Zgoda klienta — osoba, której dane pozyskujesz, musi wyrazić zgodę na ich pobieranie, przechowywanie i wykorzystanie, np. w celach marketingowych.
Uwaga! RODO obowiązuje wyłącznie mieszkańców Unii Europejskiej, więc nie ma zastosowania m.in. w USA czy Japonii.
Przestrzegaj praw autorskich
Prawa autorskie to wyłączne prawo do dzieła — artykułu, zdjęcia, filmu czy utworu muzycznego. Ponieważ wiele danych w internecie stanowi treści chronione, podczas scrapowania łatwo je naruszyć. Istnieją jednak wyjątki, w których możesz wykorzystać dane bez naruszenia prawa, na przykład w ramach prawa do cytatu lub celów dydaktycznych.
Wyjątki, w których możesz scrapować i wykorzystywać dane bez naruszenia praw autorskich:
wykorzystanie na własny użytek publiczny,
wykorzystanie w celach dydaktycznych lub naukowych,
wykorzystanie w ramach prawa do cytatu.
Od czego zacząć web scraping?
Web scraping zaczynasz od trzech kroków: znajdujesz adres URL interesującej Cię strony, poznajesz strukturę jej kodu HTML za pomocą opcji „Zbadaj element" w przeglądarce oraz przygotowujesz środowisko pracy z edytorem kodu. Bez znajomości HTML trudno wskazać konkretny element, który chcesz pobrać ze strony konkurencji i przenieść do własnego projektu.
Znajdź adres URL — określ tematykę i wskaż stronę, która Cię interesuje; ogranicza Cię tylko wyobraźnia i dostępność źródeł danych.
Poznaj kod HTML — użyj opcji „Zbadaj element" w przeglądarce, aby zobaczyć znaczniki i zidentyfikować interesujący Cię fragment strony.
Przygotuj środowisko pracy — zainstaluj edytor kodu, np. Visual Studio Code, Notepad++ (Windows), TextEdit (macOS) lub Sublime Text.
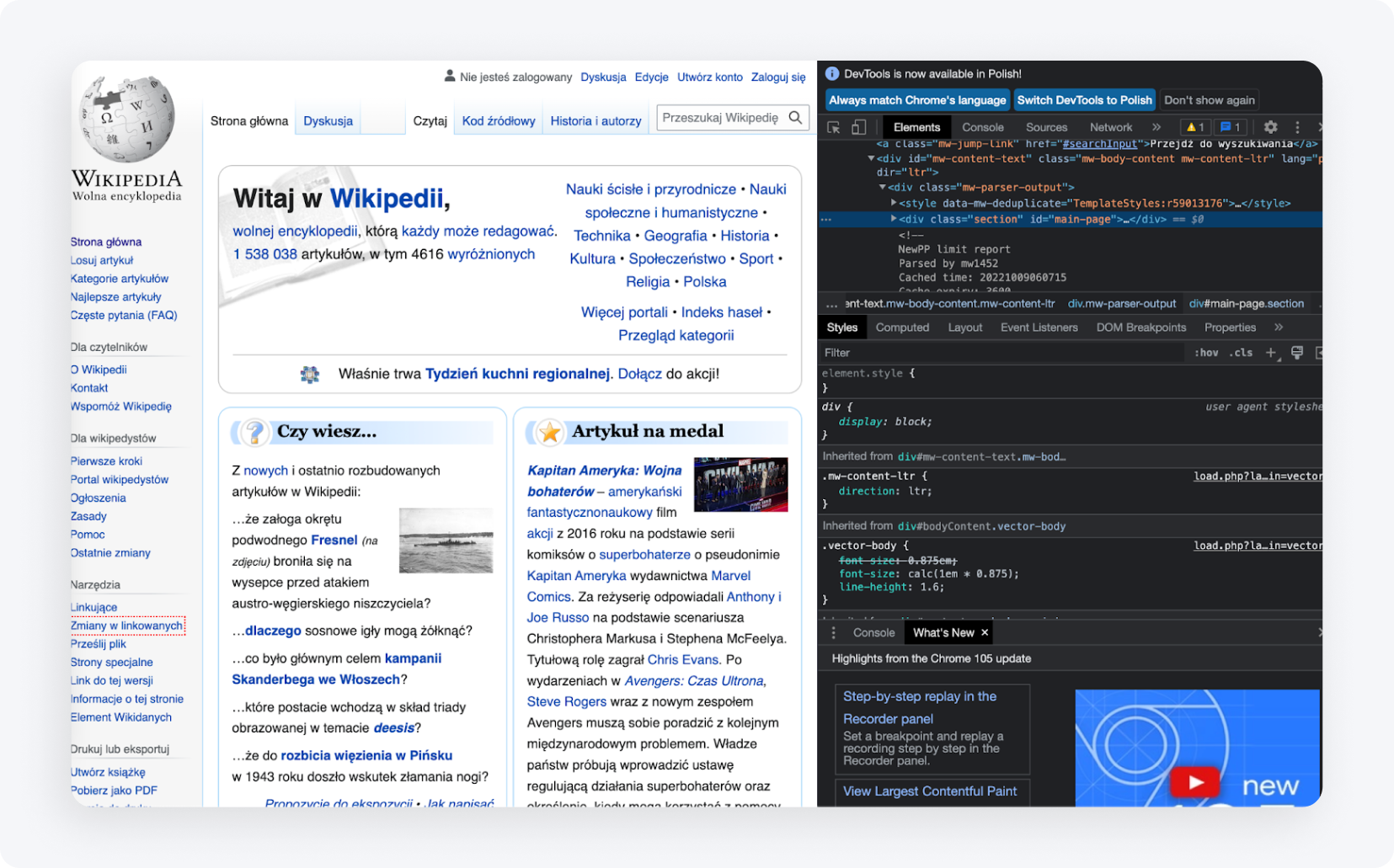
Po najechaniu myszką na wiersz kodu w przeglądarce podświetla się odpowiadający mu element na stronie — tak najszybciej zidentyfikujesz fragment do pobrania.
Jakie narzędzia i biblioteki wybrać do web scrapingu?
Wybór narzędzia do web scrapingu zależy od Twoich umiejętności programistycznych i skali projektu. Programiści sięgają po biblioteki w Pythonie (Beautiful Soup, Scrapy) lub PHP (Simple HTML DOM Parser), które dają pełną kontrolę nad ekstrakcją danych. Początkujący wybierają narzędzia no-code z interfejsem wizualnym oraz gotowe usługi online.
Biblioteki do web scrapingu (Python i PHP)
Biblioteki do web scrapingu to gotowe zbiory skryptów i funkcji, które automatyzują pobieranie danych ze stron. Pozwalają analizować, filtrować i ekstrahować treść z kodu HTML lub XML bez pisania każdej funkcji ręcznie. Najpopularniejsze to Beautiful Soup i Scrapy w Pythonie oraz Simple HTML DOM Parser w PHP.
Beautiful Soup (Python) — biblioteka do parsowania HTML i XML; ułatwia nawigację, wyszukiwanie i modyfikację drzewa DOM oraz wyciąganie danych ze stron.
Scrapy (Python) — framework do budowy robotów, które przeszukują strony, podążają za linkami i zapisują dane w wybranych formatach; idealny do złożonych projektów.
Simple HTML DOM Parser (PHP) — narzędzie dla programistów PHP do wyszukiwania, modyfikacji i ekstrakcji fragmentów kodu HTML.
Narzędzia bez kodowania (no-code)
Narzędzia no-code umożliwiają web scraping bez pisania kodu — dane wskazujesz bezpośrednio w przeglądarce, a program zbiera je automatycznie. Dzięki wizualnym interfejsom skopiujesz całą stronę lub wyeksportujesz wybrane dane do Excela albo formatu JSON bez znajomości programowania. To wygodne rozwiązanie dla wydawców, którzy cenią czas i prostotę obsługi.
Więcej rozwiązań znajdziesz w zestawieniu narzędzi dla wydawcy, a o ukrywaniu śladów przeczytasz w tekście o przeglądarkach anty-detect.
ZennoPoster — automatyzacja i scraping z wizualnym interfejsem dla nie-programistów. Cena: $37/mies, z 14-dniowym okresem próbnym.
Browser Automation Studio (BAS) — przyjazny program do automatyzacji przeglądarki z wbudowanymi narzędziami do tworzenia skryptów. Cena: darmowy.
Octoparse — zbieranie dużych ilości danych metodą wizualną; darmowa wersja ma limit 10 zadań i 10 tys. wierszy eksportu, płatne plany od $75/mies.
import.io — chmurowe narzędzie strukturyzujące dane i eksportujące je do Excela lub JSON. Darmowe demo, płatne pakiety od $399/mies.
ProWebScraper — usługa kopiowania witryn z wersją testową na 100 stron; płatność od $40/mies zależnie od liczby scrapowanych stron.
Jakie usługi online umożliwiają web scraping?
Usługi online do web scrapingu działają w przeglądarce, bez instalowania programu na komputerze. Wprowadzasz adres URL strony, ustawiasz opcje (zapis HTML, CSS, JavaScript i fontów, kopia wersji mobilnej, zmiana nazw plików) i pobierasz gotowe archiwum. Dzięki temu webmaster zapisze dowolny landing page, a potem wprowadzi własne poprawki.
Save a Web 2 ZIP — najpopularniejszy, w pełni darmowy serwis przeglądarkowy. Podajesz link, wybierasz opcje i pobierasz kopię strony.

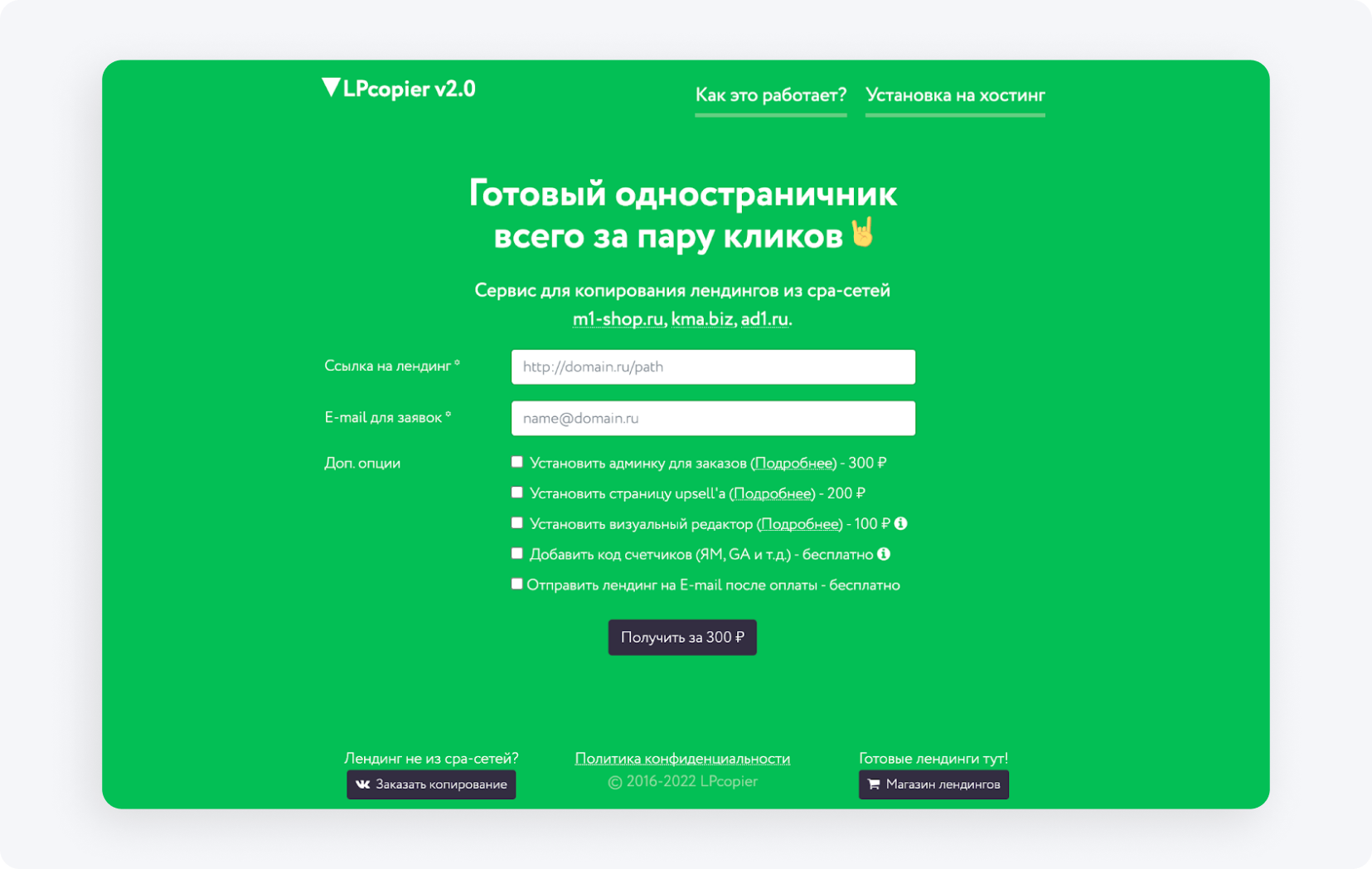
LPcopier — rosyjska usługa nastawiona na afiliację; scrapowanie już od ~25 zł za stronę, z opcją zamówienia gotowego landing page'a (dostępne tłumaczenie Google).
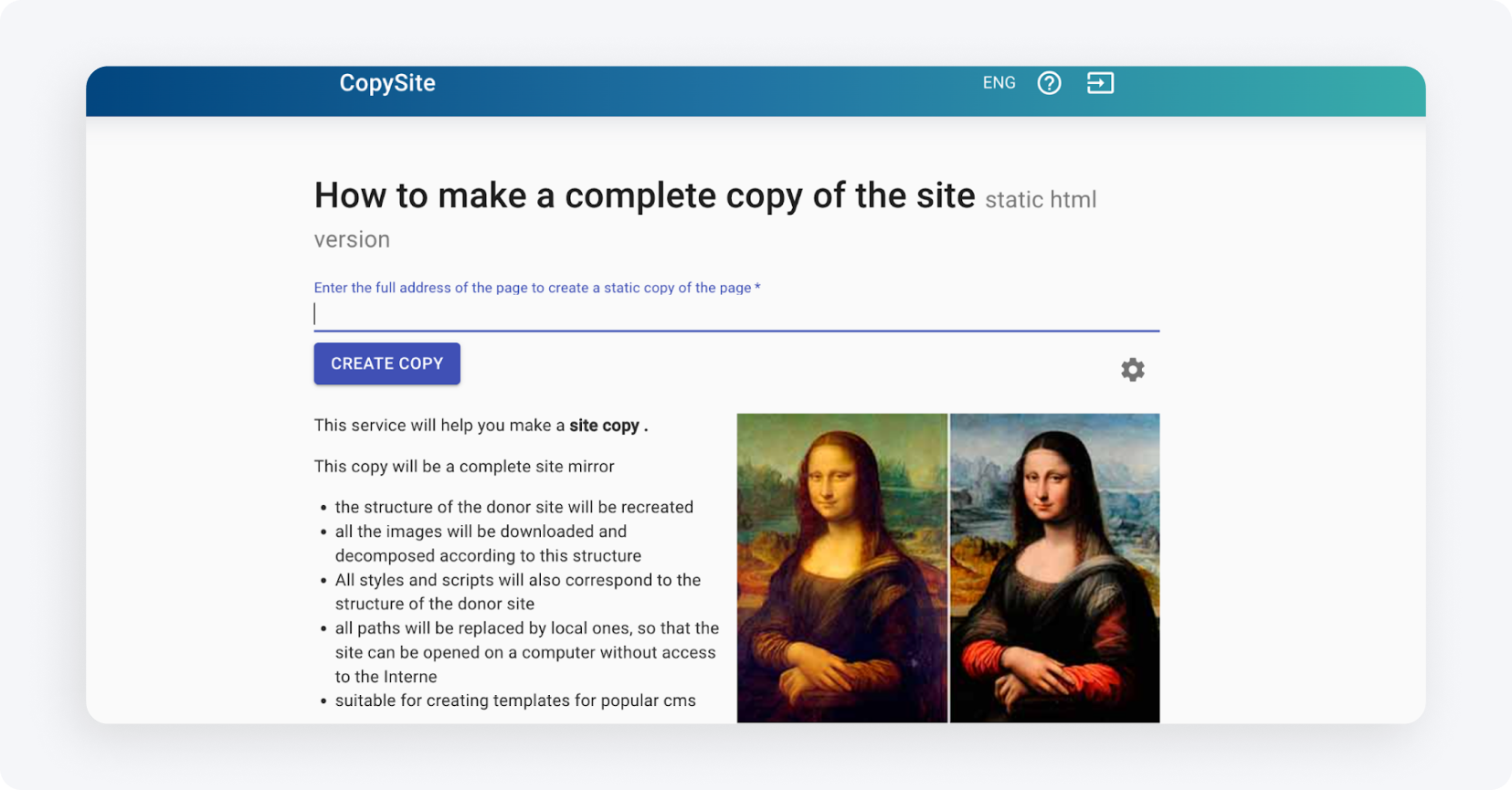
Xdan (CopySite) — rosyjski serwis (dostępny po angielsku) tworzący bezpłatnie lokalną kopię landing page z możliwością usunięcia liczników i podmiany linków lub domen.
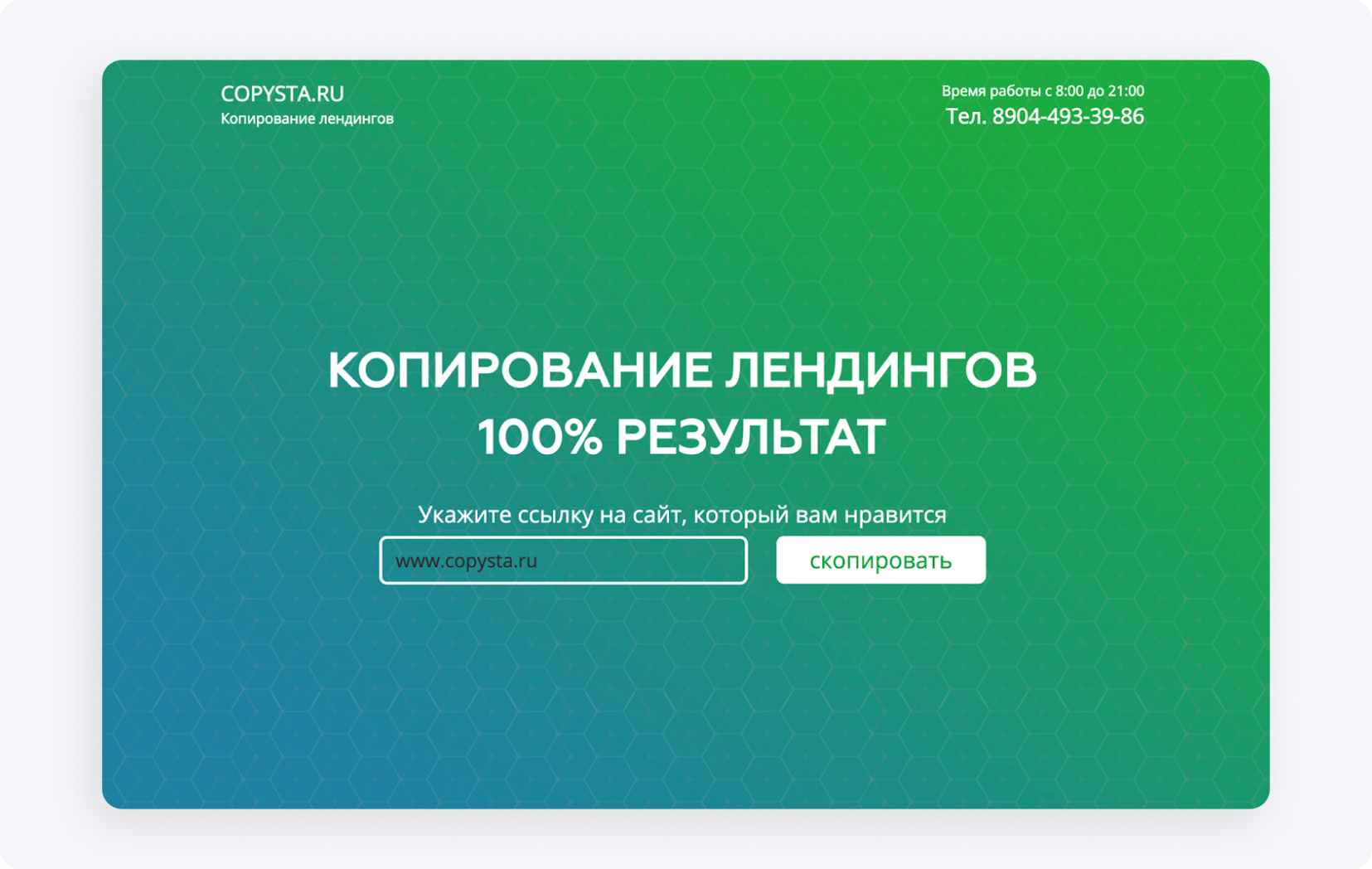
Copysta — jedna z najszybszych usług tego typu; deklaruje kontakt w 15 minut, a scraping odbywa się przez link.
Co zrobić z pobraną stroną WWW?
Po pobraniu strony WWW musisz ją zmodyfikować pod własną kampanię i bezpiecznie wgrać na hosting. Najpierw dostosowujesz kod w edytorze (Visual Studio Code, Notepad++, Sublime Text), zmieniasz wygląd przez CSS i dodajesz własne elementy. Następnie usuwasz cudze linki partnerskie i skrypty, dopiero potem przesyłasz stronę na serwer.
Jak przerobić zapisaną stronę?
Aby przerobić skopiowaną stronę, otwierasz jej kod w edytorze umożliwiającym pracę z HTML i CSS, a następnie dostosowujesz układ, dodajesz formularze, przyciski akcji i własne linki. Po zapisaniu pliku widzisz zmiany w przeglądarce. Pomocne są też serwisy jak Archivarix, które odtwarzają i archiwizują cały projekt strony.
Edytuj znaczniki HTML za pomocą CSS, dodawaj formularze, przyciski akcji i linki, a po zapisaniu sprawdzaj efekt w przeglądarce. Zanim uruchomisz kampanię, przetestuj wersje strony — sprawdź, jak działają testy A/B, i zadbaj o optymalizację konwersji.
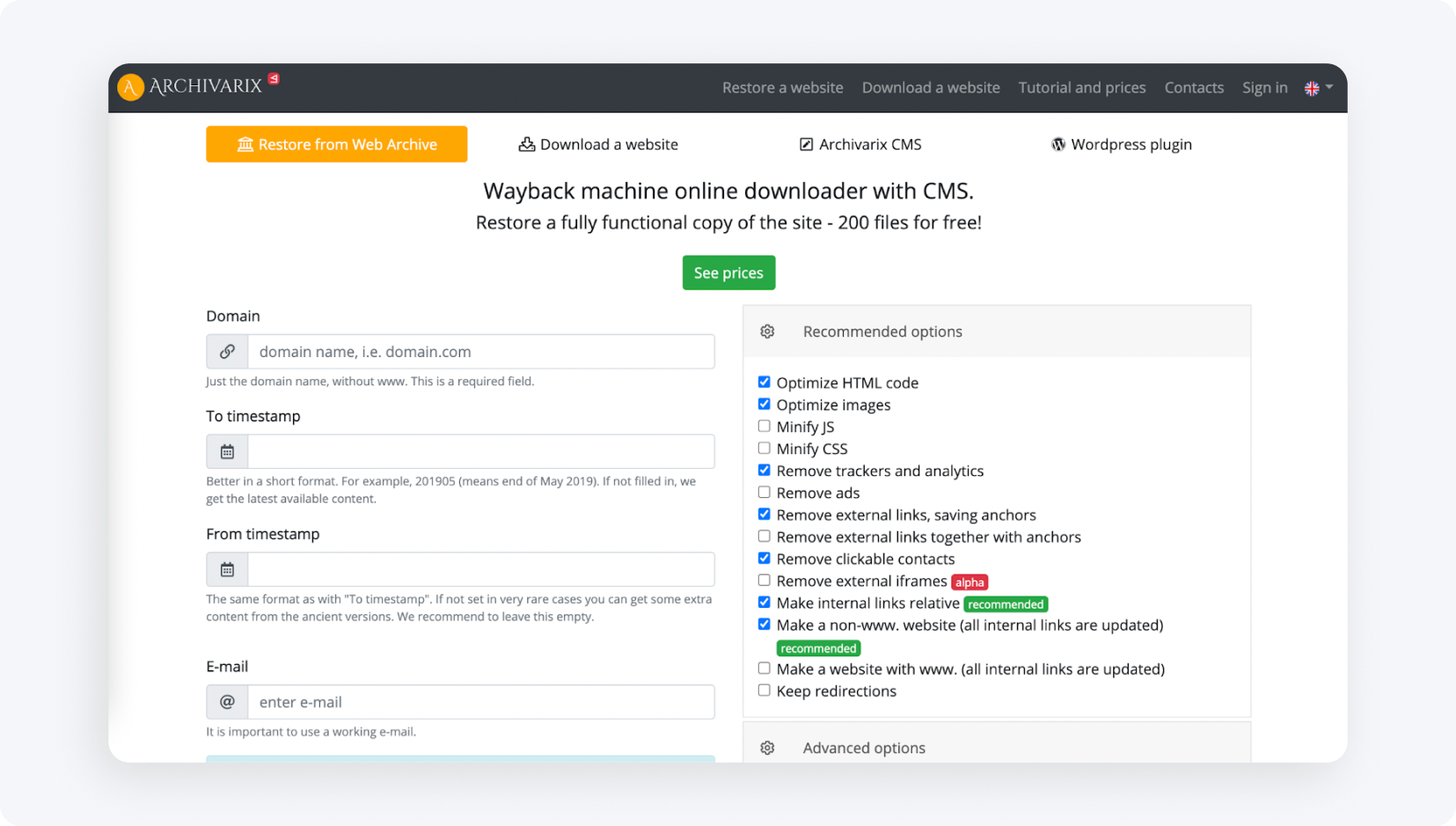
Wgrywanie strony na hosting
Wgrywanie strony na hosting to ostatni i najważniejszy krok web scrapingu landing page. Sama kopia z drobnymi zmianami wizualnymi nie wystarczy — w kodzie niemal zawsze zostają cudze linki partnerskie, skrypty, piksele wymiany i kody liczników analitycznych. Musisz je usunąć ręcznie lub płatnym programem przed przesłaniem na serwer.
Jak bronić się przed web scrapingiem?
Aby bronić się przed web scrapingiem, zabezpieczasz witrynę kilkoma metodami ograniczającymi dostęp botów. Najczęściej stosujesz plik robots.txt, blokady w .htaccess, tokeny CSRF w formularzach, filtrowanie adresów IP oraz CAPTCHA. Żadna metoda nie daje stuprocentowej ochrony, ale ich połączenie znacząco utrudnia automatyczne pobieranie Twoich danych przez niechciane boty.
robots.txt — wskazuje robotom, które części witryny mogą przeszukiwać; uczciwe boty go respektują, ale nie gwarantuje pełnej ochrony.
.htaccess — blokuje dostęp określonym User Agentom wykorzystywanym przez boty.
CSRF (Cross-Site Request Forgery) — tokeny w formularzach zabezpieczają interakcje przed automatycznym scrapowaniem.
Filtrowanie adresów IP — ogranicza dostęp do witryny tylko dla wybranych adresów IP.
CAPTCHA — utrudnia botom automatyczną interakcję z formularzami; jedna z najpopularniejszych metod obrony.
mod_qos — na serwerach Apache ustawia limity liczby żądań z jednego adresu IP w danym czasie.
Scrapshield — usługa CloudFlare wykrywająca i blokująca działania web scrapingowe.
Jeśli Twój landing page padł ofiarą scrapingu, prostym kodem JavaScript (dostępnym na forum Afflift) sprawisz, że część ruchu i tak wróci na Twoją stronę.
Kluczowe wnioski
Web scraping pozwala pobrać i przerobić landing page konkurencji, oszczędzając godziny pracy nad własną kampanią afiliacyjną.
Scrapowanie pozostaje legalne, dopóki przestrzegasz praw autorskich oraz przepisów RODO — naruszenie grozi karą nawet do 2 lat pozbawienia wolności.
Do scrapingu bez kodu użyjesz narzędzi no-code, a programiści sięgają po Beautiful Soup lub Scrapy w Pythonie.
Darmowe usługi online, jak Save a Web 2 ZIP, kopiują landing page bezpośrednio w przeglądarce, bez instalacji programu.
Przed wgraniem skopiowanej strony na hosting usuń cudze linki partnerskie, skrypty i piksele wymiany.
Własną witrynę zabezpieczysz przed scraperami m.in. plikiem robots.txt, CAPTCHA i usługą Scrapshield.
FAQ
1. Czym jest web scraping?
Web scraping to proces automatycznego pobierania danych ze stron internetowych za pomocą botów, skryptów lub specjalnych narzędzi.
2. Czy web scraping jest legalny?
Tak, sama technologia jest legalna. Musisz jednak przestrzegać praw autorskich oraz przepisów o danych osobowych, np. RODO.
3. Do czego wykorzystuje się web scraping?
Najczęściej do zbierania danych z internetu, analizy rynku, monitorowania cen, analizy opinii klientów i kopiowania struktur stron.
4. Czy web scraping jest przydatny w afiliacji?
Tak. Pomaga analizować landing page konkurencji, zbierać dane marketingowe i szybciej testować kampanie afiliacyjne.
5. Jak zacząć web scraping?
Poznaj podstawy HTML, wybierz odpowiednie narzędzie lub bibliotekę i określ, jakie dane chcesz pobierać ze strony.
Podsumowanie
Web scraping to skuteczny sposób na szybkie pobranie i przerobienie landing page konkurencji, ale wymaga przestrzegania praw autorskich oraz RODO. Wybierz narzędzie dopasowane do swoich umiejętności — bibliotekę w Pythonie, narzędzie no-code lub usługę online — i pamiętaj o usunięciu cudzych skryptów przed publikacją. Załóż darmowe konto wydawcy w MyLead i wykorzystaj zaoszczędzony czas na testowanie kampanii.
Masz pytania? Skontaktuj się z nami za pośrednictwem naszych kanałów.