
Blog / Affiliate marketing
Web Scraping in Affiliate Marketing: How to Download a Website?
This article is updated regularly
Last update:
13 March 2025
Web scraping is the automated copying of websites and their data to a local computer using bots, an indexing robot, or a Python script. In affiliate marketing, it serves to download a competitor's landing page, save preparation time, and adapt the copy to a new campaign — always within the limits of copyright and data-protection law.
This guide walks you through the legal rules, the libraries and no-code tools that copy a website, and the exact steps to turn a downloaded landing page into a working affiliate asset.
What you'll learn from this article:
what web scraping is and how it works in practice,
why copying a competitor's landing page saves time in affiliate marketing,
whether web scraping is legal and how the GDPR and copyright apply,
which libraries, no-code tools, and online services copy a website,
how to redesign a downloaded page, upload it to hosting, and protect your own site.
What is web scraping and how does it work?
Web scraping is the automated extraction of data from websites and the saving of that data to a local database. The process runs through bots, an indexing robot, or a script written in Python. It copies entire pages or specific elements — prices, reviews, product details — and converts them into structured formats ready for analysis.
Businesses use scraped data to monitor competitor prices, track consumer trends, and study how visitors navigate a site. Analysts in fields from market research to medicine pull data from public sources to spot patterns and test hypotheses. In affiliate marketing, the target is almost always a landing page.
How does web scraping help in affiliate marketing?
In affiliate marketing, web scraping saves time by allowing a competitor's landing page to be downloaded instead of built from scratch. A high-converting landing page drives return on investment, and reusing a proven layout shortens the path to launch. The downloaded copy becomes the base for further customization to a specific offer.
You can use landing pages supplied by your affiliate network, ready-made templates from page builders, or a page coded from scratch. The first two options run out fast under heavy competition, so following clear rules for an effective landing page matters more than where you start.
As an alternative to copying, you can generate fresh pages with AI-built landing pages in several languages at once. Sign up for a free MyLead publisher account — MyLead is an affiliate network that connects publishers with campaigns across many niches.
Is web scraping legal?
Web scraping stays legal in 2026 when it respects copyright and the rules governing access to data. Companies scrape publicly available information lawfully every day. It crosses into illegality when it copies copyrighted content for resale, undercuts pricing unfairly, or harvests protected personal data. The line sits at how data is collected and used.

Scraping within the rules is fine. The moment you cross into a darker approach that MyLead does not accept — piracy, stealing content, or scraping behind logins — you face real legal consequences.
Does the GDPR apply to web scraping?
The GDPR applies whenever scraping involves personal data belonging to residents of European Union countries. Personal data is any information that identifies a person. When no personal data is collected, the regulation has little bearing. Lawful processing requires a valid legal ground for storing that data.
Personal data includes, for example:
first and last name,
email address,
phone number,
home address,
username (login or nickname),
IP address,
credit or debit card number,
medical or biometric data.
To store personal data lawfully, you need a valid reason. Two grounds cover most cases:
Legitimate interest — you prove the processing is necessary for a legitimate business purpose that does not override the person's rights and freedoms.
Customer consent — each person consents to the collection, storage, and use of their data for your stated purpose, such as marketing.
Without a legitimate interest or consent, you breach the GDPR, which carries a fine, a restriction of freedom, or imprisonment for up to two years. The GDPR covers only residents of EU countries, so it does not apply to places such as the United States, Japan, or Afghanistan.
How does copyright apply to web scraping?
Copyright is the exclusive right to a created work — an article, photo, video, or piece of music. Much of the data online is copyrighted, which makes copyright central to web scraping. Limited exceptions allow scraping and reuse without infringement, mainly for personal use, education or research, and quotation under the right to quote.
use for personal, public use,
use for didactic purposes or scientific activity,
use under the right to quote.
Web scraping — where do you start?
Web scraping starts with three things: the URL of the target page, a working knowledge of HTML, and a prepared work environment. The URL defines what gets copied, HTML reveals which elements to extract, and a code editor handles the edits. With these in place, the actual extraction becomes a repeatable process.
URL — find the address of the page you want and define your topic; your imagination and data sources are the only limits.
HTML code — learn the page structure, then open an element in your browser and use the Inspect option to read the HTML tags.
Work environment — install a text editor such as Visual Studio Code, Notepad++ (Windows), TextEdit (macOS), or Sublime Text before you start.
Hovering over a line of code highlights the matching element on the page, as you can see on Wikipedia:
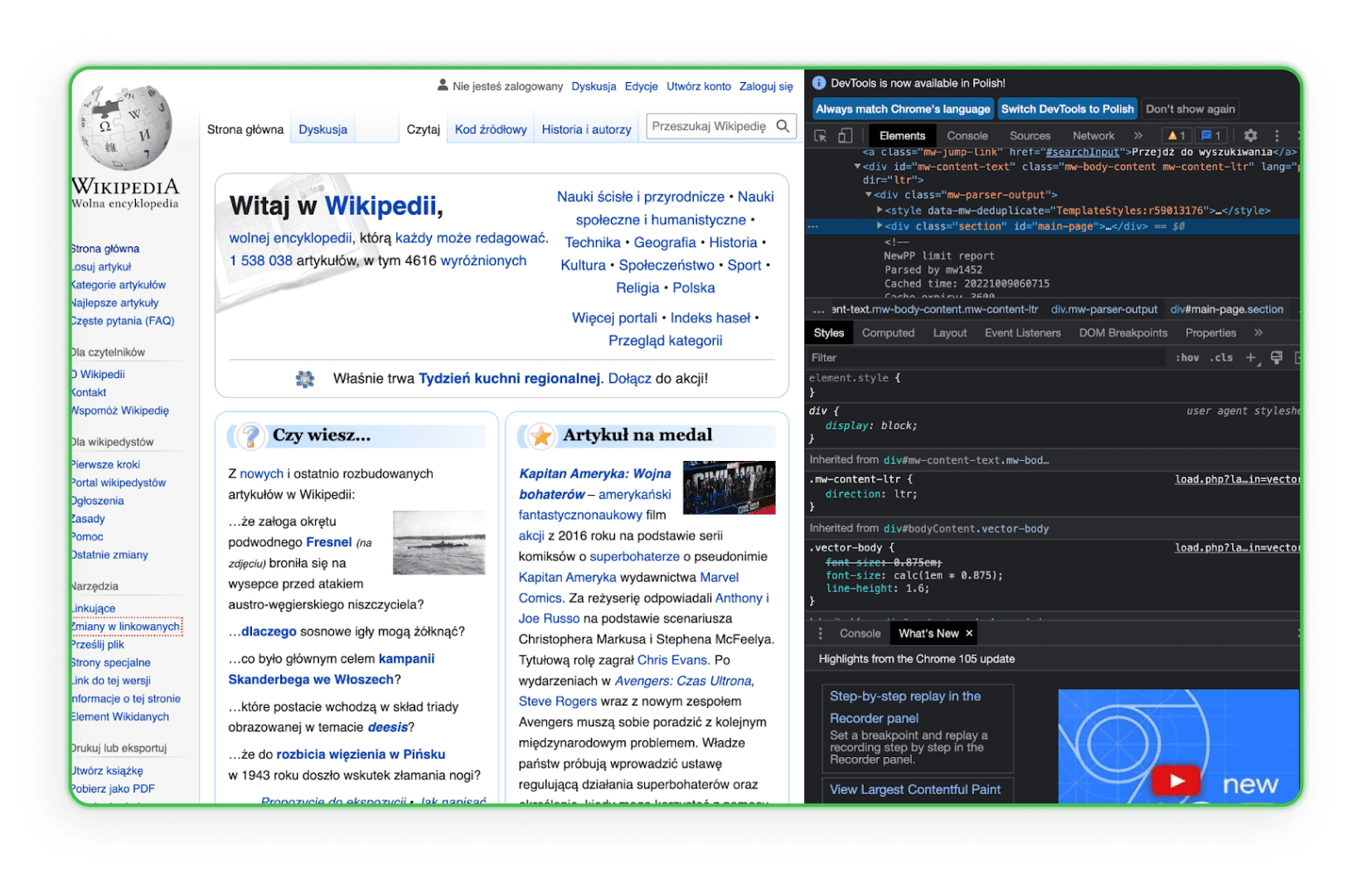
A solid setup pays off across every campaign — our roundup of top tools for affiliate publishers covers what else belongs in your kit.
Which tools and libraries are used for web scraping?
Web scraping libraries are organized collections of scripts and functions in a given programming language that pull data from websites automatically. They let developers parse, filter, and extract content from HTML or XML without writing every function by hand. Beyond code libraries, no-code tools and browser-based options cover users with no programming background.
Programming libraries for developers
Programming libraries suit developers who write their own scraping logic. Each one targets a language and a use case, from quick HTML edits to full crawling frameworks that follow links across a site. Three libraries dominate affiliate and data work, alongside the simplest option of all — saving a page straight from the browser.
Simple HTML DOM Parser — a PHP library for searching, modifying, and extracting sections of HTML code intuitively.
Beautiful Soup — a Python library for parsing HTML and XML documents and navigating the DOM tree to extract data.
Scrapy — a powerful Python framework that builds bots which scan pages, follow links, extract data, and save it in chosen formats.
Anyone can save a page straight from the browser in a few minutes; it produces an HTML file and a folder, though large sites force you to repeat the process many times. Paid services such as ProWebScraper handle the work for you — a trial covers 100 pages, and plans start from $40 monthly depending on volume.
No-code tools for beginners
No-code tools collect website data through visual interfaces, with no programming required. They suit affiliate marketers who want results without learning to code. Pricing ranges from free to several hundred dollars a month, and the right pick depends on volume, export limits, and how much technical support is included.
| Tool | Price | Coding required |
|---|---|---|
| ZennoPoster | from $37/month (14-day trial) | No |
| Browser Automation Studio (BAS) | Free | No |
| Octoparse | Free version; paid from $75/month | No |
| import.io | Free demo; paid from $399/month | No |
Octoparse's free plan stores ten tasks, runs only on local devices using your own IP, and caps exports at 10,000 rows per run, with limited technical support. For a wider comparison, browse our list of 17 tools for affiliate publishers.
What online services let you copy a landing page?
Online web scraping services copy a landing page directly in the browser, with nothing to install. The principle is simple: enter the page URL, choose settings such as copying the mobile version or renaming assets, and download an archive of the HTML, CSS, JavaScript, and fonts. The webmaster then reformats and corrects the saved copy.
Save a Web 2 ZIP — the most popular browser-based scraping service. Its simple, well-thought-out design inspires confidence, and it is completely free; you paste the link, pick your options, and the copy is ready.

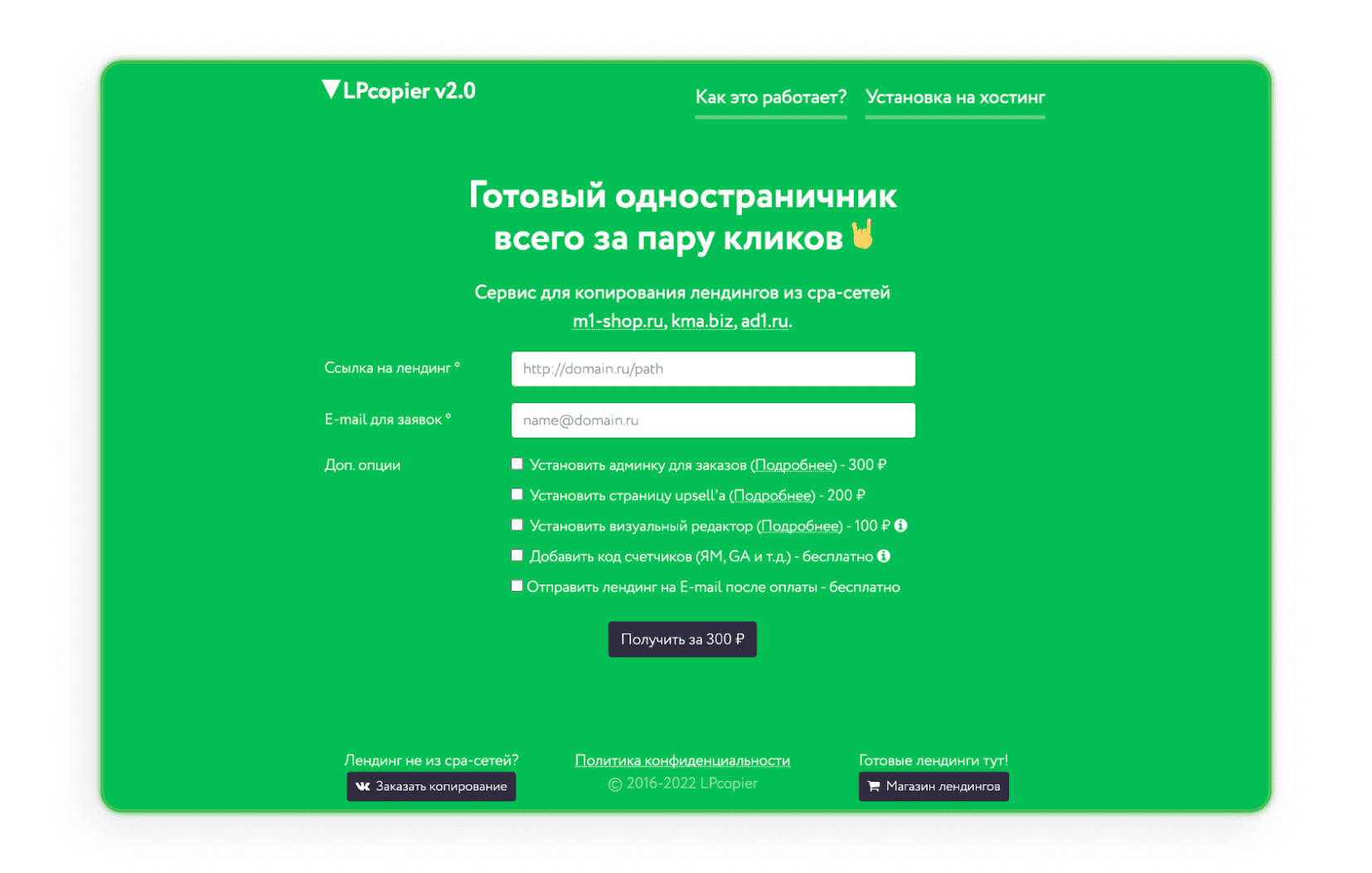
LPcopier — a Russian service aimed at affiliate marketing. It copies a page for about $5, with extras like analytics counters priced separately. You can also order a landing page outside a CPA network, and a translation tool handles the language barrier.
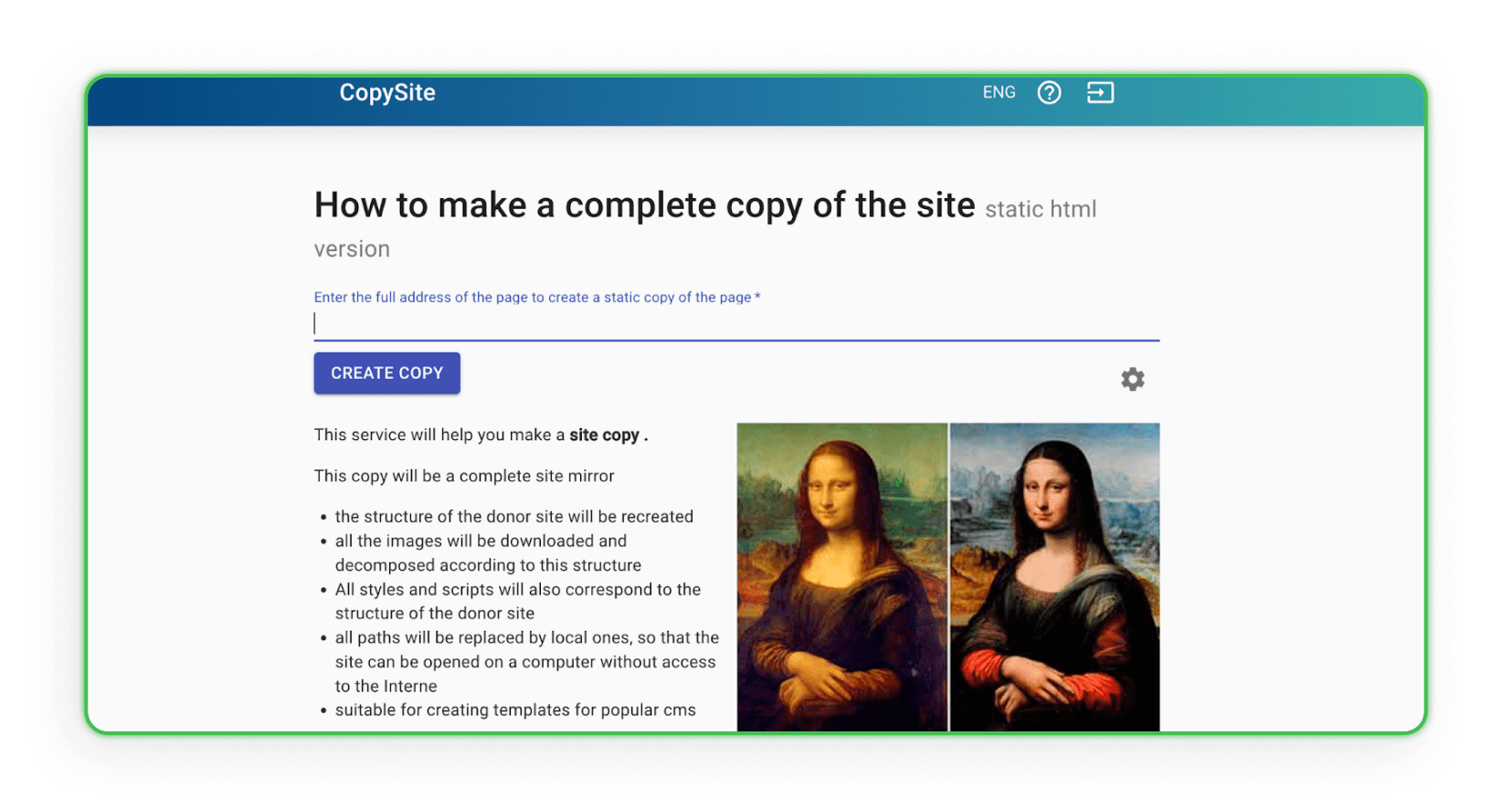
Xdan — another Russian site, available in English, offering CopySite. It builds a local copy of a landing page for free, with options to clean HTML counters or replace links and domains.
Copysta — one of the fastest services of its kind; it promises contact within 15 minutes. Scraping runs through a link, and you can update the copied site for an extra fee.

You downloaded the website — how do you redesign it?
After downloading a website, the next step is redesigning the copy to fit a new campaign. Editing happens in a code editor, where HTML structure, CSS styling, forms, buttons, and links are all customized. Saved changes appear instantly in the browser. Archiving tools can also restore and rebuild full projects from web archives.
To customize the copy, duplicate the asset and open a code editor such as Visual Studio Code, Notepad++ (Windows), TextEdit (macOS), or Sublime Text. Edit the HTML tags with CSS, add web forms, action buttons, and links, then save and check the result. For deeper changes, our guide to landing page design tricks walks through the details.
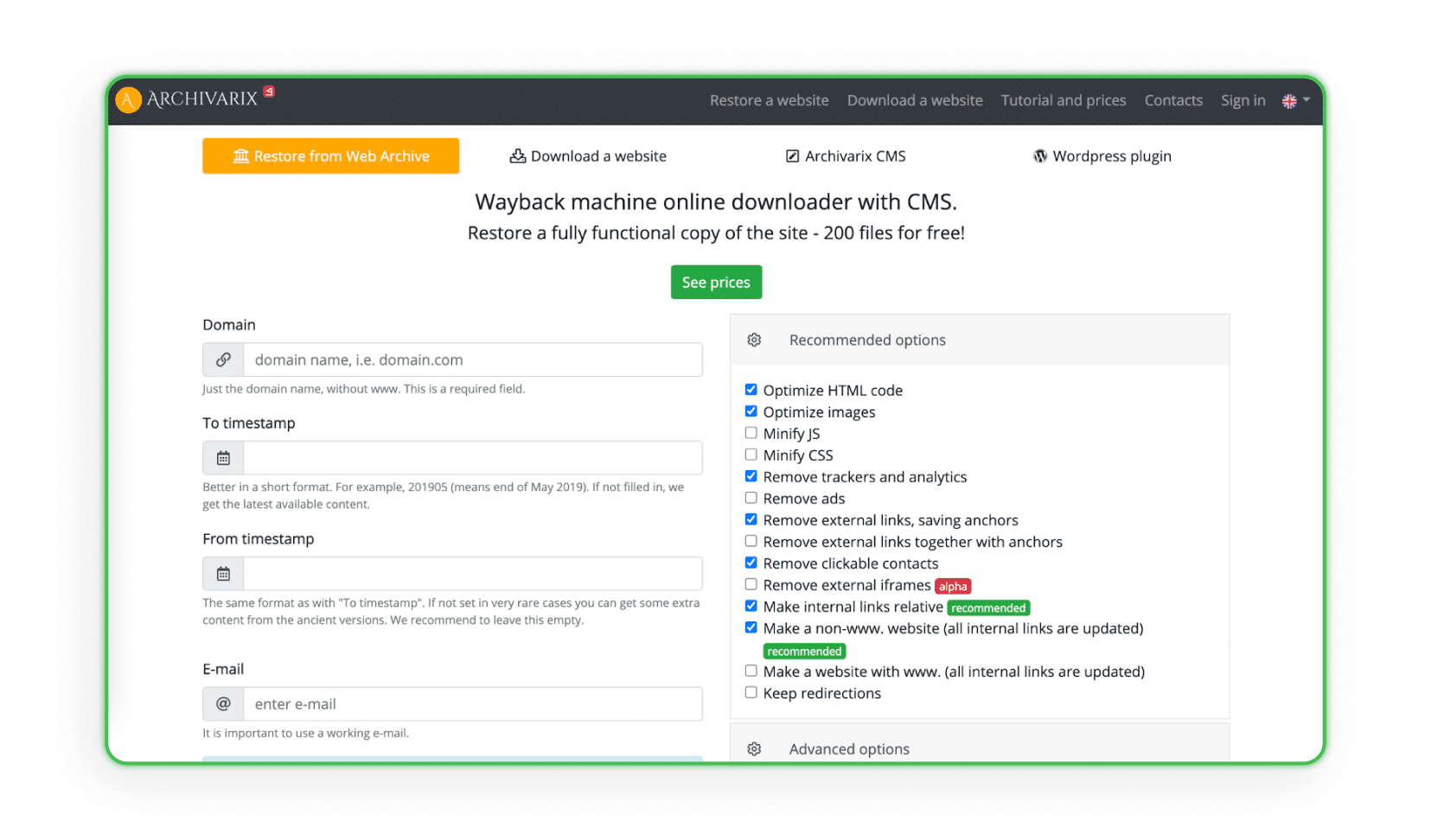
Some platforms pull design data from web archives and rebuild the project inside a content management system. Archivarix is one example — it restores and archives full pages from the Wayback Machine, with 200 files free.
How do you upload the copied page to hosting?
Uploading the page to hosting is the final and most important step in web scraping a landing page. A copied page still contains other people's affiliate links, scripts, replacement pixels, and analytics codes. These must be removed manually, or with paid tools, before upload. Only then does the page work as your own asset.
Copying and tweaking the visuals is not enough — leftover tracking codes send conversions to the original owner. Once the page is clean, follow our walkthrough on how to create a landing page step by step to publish it, then apply these landing page SEO tips so it pulls organic traffic.
How do you protect your site against web scraping?
Protecting a site against web scraping combines several technical methods, since no single tool blocks every bot. Server rules, access filters, and challenge mechanisms together cut the risk. Honest bots respect signals like robots.txt, while aggressive scrapers need harder barriers such as CAPTCHA, rate limiting, and dedicated anti-scraping services.
Robots.txt — tells search robots which parts of your site to crawl; honest bots follow it, though it guarantees nothing against rogue scrapers.
.htaccess — blocks access for specific User Agents that bots use.
CSRF tokens — secure forms and interactions against automated scraping.
IP address filtering — limits access to specific IP addresses to reduce scraping.
CAPTCHA — one of the most popular defenses; makes automated interaction difficult.
Rate limiting with mod_qos — caps requests per IP within a time window on Apache servers.
Scrapshield — Cloudflare's tool for detecting and blocking scraping activity.
If your landing page falls victim to scraping, you can redirect some of that traffic back to your own page. A short JavaScript snippet, shared on the Afflift forum, protects you from losing traffic entirely when a page is copied.
Key takeaways
Web scraping copies websites and data to a local machine using bots, an indexing robot, or a Python script.
In affiliate marketing, it shortcuts landing page creation by copying and customizing a proven competitor page.
It is legal only when you respect copyright; the GDPR applies to personal data of EU residents, and breaches carry fines or up to two years' imprisonment.
Tool choice scales with skill: libraries like Beautiful Soup and Scrapy for coders, no-code tools like Octoparse for beginners, and browser services like Save a Web 2 ZIP for one-click copies.
Before publishing, strip every leftover affiliate link, pixel, and analytics code, or conversions flow to the original owner.
Defend your own pages with layered methods — robots.txt, CAPTCHA, IP filtering, rate limiting, and Cloudflare's Scrapshield.
FAQ
1. How much does it cost to scrape a website?
Browser tools like Save a Web 2 ZIP and Xdan are free. Paid options range from about $5 per page on LPcopier to subscription tools priced from $37 to $399 a month.
2. What is the easiest way to download a website?
The easiest way is a browser service like Save a Web 2 ZIP: paste the URL, choose your options, and download a ZIP of the page's HTML, CSS, and assets — no coding needed.
3. Which library is best for web scraping in Python?
Beautiful Soup suits simple HTML and XML parsing, while Scrapy fits larger crawls that follow links across a site. Most affiliate marketers start with Beautiful Soup.
4. Does the GDPR apply if I scrape a US website?
No, the GDPR covers only residents of EU countries. Scraping data from US, Japanese, or other non-EU users falls outside it, though local laws still apply.
5. Can a website block web scraping?
Yes. Methods like robots.txt, CAPTCHA, IP filtering, rate limiting, and Cloudflare's Scrapshield reduce scraping, though no single method stops every bot.
Summary
Web scraping gives affiliate marketers a fast, legal way to download and customize landing pages — as long as you respect copyright and the GDPR. Pick the right tool for your skill level, strip every leftover tracking code before publishing, and protect your own pages in return. Start applying these tactics with a free MyLead publisher account.
Have any questions? Feel free to reach us through our channels.