
Blog / Affiliate marketing
Web-Scraping für Affiliate-Marketing: Ein Leitfaden zum Herunterladen und Anpassen einer Website nach Ihren Bedürfnissen.

Was ist Web Scraping?
Web Scraping bedeutet, Websites als Kopien auf einen Computer herunterzuladen. Diese Technologie wird verwendet, um ganze Websites herunterzuladen und bestimmte, interessante Daten aus einem Portal zu extrahieren. Der gesamte Prozess wird mit Bots, einem Indexierungsroboter oder einem in Python geschriebenen Skript durchgeführt. Während Produkt- oder Dienstleistungsbewertungen auf verschiedenen Plattformen. Dies hilft, Muster im Zusammenhang mit dem Kundenzufriedenheitsniveau und Bereichen zu erkennen, die verbessert werden müssen. Gleichzeitig können Marktforschungsunternehmen Daten zu Produkt- und Dienstleistungspreisen, Verkaufsvolumen und Verbrauchertrends sammeln, was bei der Preisstrategie und Planung von Marketingmaßnahmen hilft.
Dank Web Scraping können Analysten auch Untersuchungen zum Verhalten der Website-Benutzer durchführen, indem sie Aspekte wie Navigation, Interaktionen und auf einzelnen Seiten verbrachte Zeit analysieren. Dies kann helfen, die Benutzeroberfläche zu optimieren, das Nutzererlebnis zu verbessern und Bereiche zu identifizieren, die weiterer Verbesserungen bedürfen.
In der Medizin und wissenschaftlichen Forschung kann Web Scraping Daten aus wissenschaftlichen Publikationen, klinischen Studien oder medizinischen Websites sammeln. Dies ermöglicht die Analyse von Gesundheitstrends, die Untersuchung der Wirksamkeit von Therapien oder die Identifizierung von Entdeckungen.
Zusammenfassend eröffnet Web Scraping als Werkzeug zur Datensammlung für Analysen Möglichkeiten für ein tieferes Verständnis von Phänomenen, Zusammenhängen und Trends in verschiedenen Bereichen. Es ist jedoch wichtig, die ethischen und rechtlichen Aspekte des Web Scrapings zu beachten, Vorsicht walten zu lassen und die Regeln einzuhalten, die den Zugang zu öffentlichen und privaten Daten regeln.
Web Scraping im Affiliate Marketing
Wie steht Web Scraping im Zusammenhang mit Affiliate Marketing? Beginnen wir mit dem wichtigsten Argument, das dazu anregt, sich für Web Scraping zu interessieren, nämlich der gesparten Zeit, die Sie durch das Herunterladen von Wettbewerber-Websites gewinnen. Jeder weiß oder ahnt zumindest, dass die Erstellung einer guten Landingpage zeitaufwendig sein kann und dass der Erfolg unter anderem von der Zeit abhängt. Weitere Faktoren sind die Offenheit für einen neuen Ansatz, die Suche nach neuen Kampagnen, das Durchführen von Tests und Werbeanalyse. Erfolg haben diejenigen, die sich nicht mit Kleinigkeiten aufhalten, sondern nach Wegen zur Skalierung suchen. Um eine Kampagne zu starten, müssen Sie die Zielgruppe, GEO-Auswahl, Angebote usw. recherchieren und Materialien einschließlich einer Landingpage vorbereiten.
Einige bevorzugen Landingpages, die vom Affiliate-Netzwerk bereitgestellt werden, andere nutzen fertige Vorlagen von Page-Buildern und wieder andere entscheiden sich, eine Landingpage von Grund auf zu erstellen. Die ersten beiden Optionen sind am häufigsten. Manchmal können sie profitabel sein, aber dies ist eine kurzfristige Lösung, da der Wettbewerb groß ist und die Pakete mit verfügbaren Vorlagen schnell erschöpft sind.
Eine hochwertige Landingpage ist der Schlüssel zum zukünftigen Erfolg und einer guten Kapitalrendite. Es ist erwähnenswert, dass nicht jede Landingpage eines Konkurrenten das erwartete Ergebnis bringt. Es ist besser, die gewünschte Landingpage zu optimieren und dabei die Kriterien der zukünftigen Werbekampagne zu berücksichtigen.
Natürlich müssen Sie daran denken, alles legal zu tun, also nach bestimmten Regeln, über die Sie gleich mehr erfahren werden.
Ist Web Scraping legal?
Ja. Web Scraping ist nicht verboten; Unternehmen, mit denen Sie Verträge abschließen, tun dies legal. Leider wird es immer jemanden geben, der Startsool für Piraterie-Aktivitäten nutzt. Web Scraping kann verwendet werden, um unlautere Preisgestaltung zu verfolgen und urheberrechtlich geschützte Inhalte zu stehlen. Ein Website-Besitzer, der Ziel eines Scrapers ist, kann erhebliche finanzielle Verluste erleiden. Interessanterweise wurde Web Scraping von mehreren ausländischen Unternehmen verwendet, um Instagram- und Facebook-Stories zu speichern, die eigentlich zeitlich begrenzt sein sollten.
Scraping ist in Ordnung, wenn Sie das Urheberrecht respektieren und sich an die festgelegten Standards halten. Wenn Sie sich jedoch für die dunkle Seite entscheiden, die bei MyLead nicht akzeptiert wird, können verschiedene Konsequenzen folgen.
Gute Praktiken beim Scraping von Websites
Beachten Sie die DSGVO
Bezüglich der EU-Länder müssen Sie die EU-Datenschutzverordnung, allgemein bekannt als DSGVO, einhalten. Wenn Sie keine personenbezogenen Daten scrapen, müssen Sie sich darüber nicht allzu viele Gedanken machen. Zur Erinnerung: Personenbezogene Daten sind alle Daten, die eine Person identifizieren können, zum Beispiel:
• Vor- und Nachname,
• E-Mail,
• Telefonnummer,
• Adresse,
• Benutzername (z.B. Login/Nickname),
• IP-Adresse,
• Informationen über Kredit- oder Debitkartennummer,
• medizinische oder biometrische Daten.
Um Web Scraping durchzuführen, benötigen Sie einen Grund für die Speicherung personenbezogener Daten. Beispiele für solche Gründe sind:
1. Berechtigtes Interesse
Es muss nachgewiesen werden, dass die Datenverarbeitung für das berechtigte Geschäft notwendig ist. Dies gilt jedoch nicht, wenn diese Interessen durch die Interessen oder Grundrechte und Freiheiten der Person, deren Daten Sie verarbeiten möchten, überwogen werden.
2. Zustimmung des Kunden
Jede Person, deren Daten Sie sammeln möchten, muss der Erhebung, Speicherung und Nutzung ihrer Daten zu dem von Ihnen beabsichtigten Zweck zustimmen, z.B. für Marketingzwecke.
Wenn Sie kein berechtigtes Interesse oder keine Kundenzustimmung haben, verstoßen Sie gegen die DSGVO, was zu einer Geldstrafe, einer Freiheitsbeschränkung oder einer Freiheitsstrafe von bis zu zwei Jahren führen kann.
Achtung!
Die DSGVO gilt nur für Einwohner der Länder der Europäischen Union, daher gilt sie nicht für Länder wie die Vereinigten Staaten, Japan oder Afghanistan.
Beachten Sie das Urheberrecht
Das Urheberrecht ist das ausschließliche Recht an jedem erstellten Werk, z.B. einem Artikel, Foto, Video, Musikstück usw. Sie können sich vorstellen, dass das Urheberrecht beim Web Scraping sehr wichtig ist, da viele Daten im Internet urheberrechtlich geschützt sind. Natürlich gibt es Ausnahmen, in denen Sie Daten scrapen und verwenden können, ohne gegen das Urheberrecht zu verstoßen, und zwar:
• Verwendung für den privaten öffentlichen Gebrauch,
• Verwendung für didaktische Zwecke oder wissenschaftliche Tätigkeit,
• Verwendung im Rahmen des Zitatrechts.
Web Scraping – wie fängt man an?
1. URL
Der erste Schritt besteht darin, die URL der Seite zu finden, die Sie interessiert. Dann bestimmen Sie das Thema, das Sie wählen möchten. Ihre Vorstellungskraft und Datenquellen sind Ihre einzigen Grenzen.
2. HTML-Code
Lernen Sie den Aufbau des HTML-Codes kennen. Sie müssen HTML verstehen, um das Element zu finden, das Sie von den Websites Ihrer Konkurrenten herunterladen möchten. Am besten gehen Sie im Browser zum Element und verwenden die Option „Untersuchen“. Dann sehen Sie die HTML-Tags und können die gewünschte Komponente identifizieren. Hier ein Beispiel auf Wikipedia:
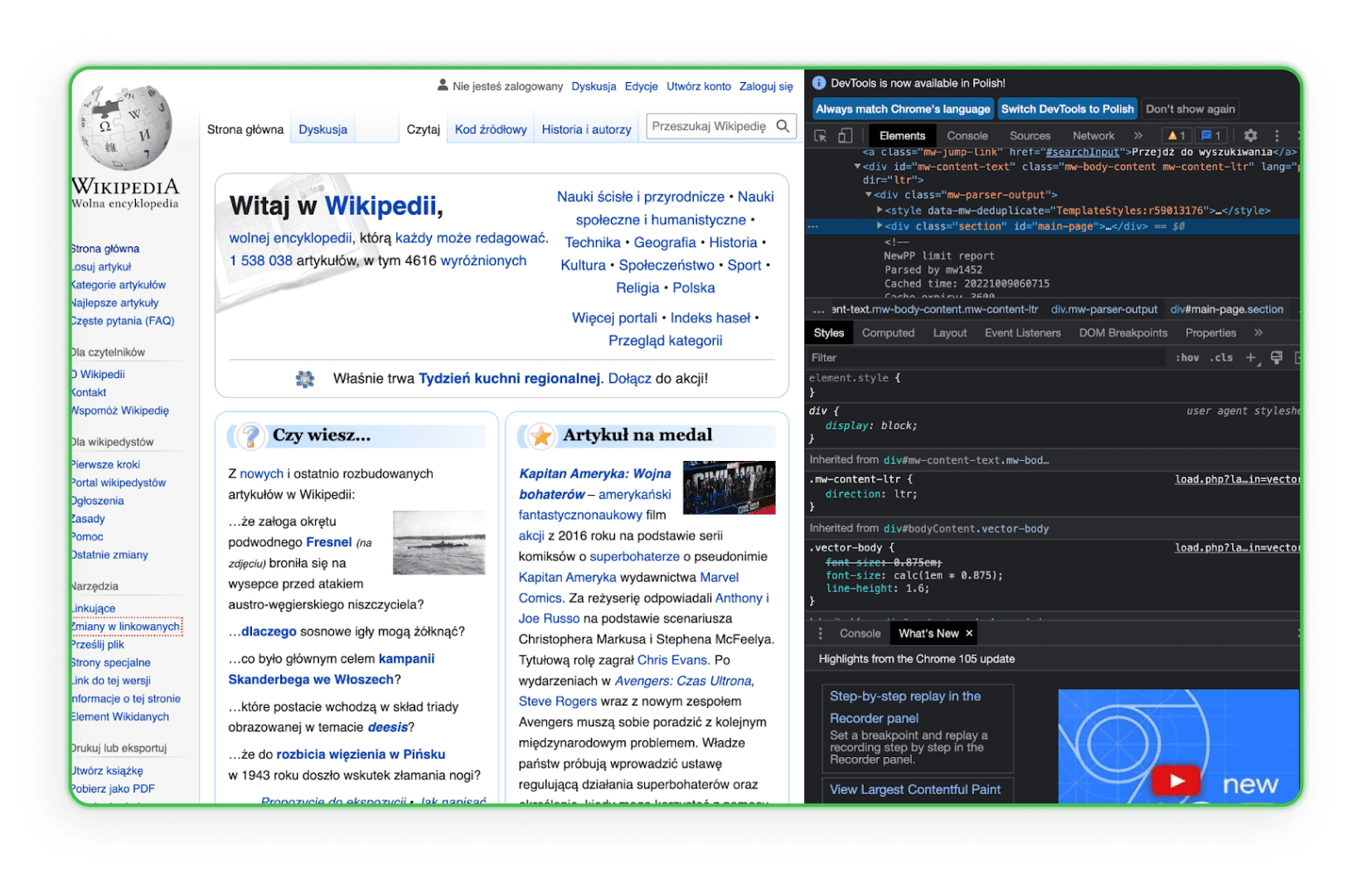
Wie Sie sehen, wird beim Überfahren einer bestimmten Codezeile das entsprechende Seitenelement hervorgehoben.
3. Arbeitsumgebung
Ihre Arbeitsumgebung sollte bereit sein. Sie werden später feststellen, dass Sie Texteditoren wie Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS) oder Sublime Text benötigen, also besorgen Sie sich einen davon.
Bibliotheken für Web Scraping – wie speichert man eine Webseite?
Web Scraping-Bibliotheken sind organisierte Sammlungen von Skripten und Funktionen, die in bestimmten Programmiersprachen geschrieben sind und beim automatischen Abrufen von Daten aus Websites helfen. Sie ermöglichen es Entwicklern, Inhalte aus dem HTML- oder XML-Code von Webseiten schnell zu analysieren, zu filtern und zu extrahieren. Mit ihnen müssen Entwickler nicht jede Funktion manuell schreiben, sondern können fertige, optimierte Lösungen für die Suche, Navigation und Manipulation der Website-Struktur verwenden.
Simple HTML DOM Parser – Eine PHP-Bibliothek
Dieses Tool richtet sich an PHP-Entwickler und erleichtert die Manipulation und Interaktion mit HTML-Code. Es ermöglicht das Suchen, Modifizieren oder Extrahieren bestimmter Abschnitte des HTML-Codes einfach und intuitiv.
Beautiful Soup – Eine Python-Bibliothek
Beautiful Soup ist eine Python-Bibliothek, die für das Parsen von HTML- und XML-Dokumenten entwickelt wurde. Sie wurde so gestaltet, dass sie das Navigieren, Suchen und Modifizieren des DOM-Baums erleichtert und intuitive Schnittstellen zum Extrahieren von Daten aus Webseiten bietet.
Scrapy – Eine Python-Bibliothek
Scrapy ist eine leistungsstarke Bibliothek und ein Framework für Web Scraping in Python. Sie ermöglicht die Erstellung spezialisierter Bots, die Seiten scannen, Links folgen, die benötigten Informationen extrahieren und diese in den gewünschten Formaten speichern können. Scrapy eignet sich perfekt für komplexere Anwendungen, die eine tiefgehende Seitensuche oder Interaktion mit Formularen und anderen Seitenelementen erfordern.
Speichern der Seite über den Browser
Jeder, auch Sie, kann die ausgewählte Seite auf seinem Computer speichern, indem er einen beliebigen Browser verwendet. Dieser Vorgang dauert nur wenige Minuten und erzeugt eine Duplikatseite als HTML-Datei und Ordner auf dem Computer des Benutzers. Die gesamte Seitenkopie wird im Browser geöffnet und sieht recht ordentlich aus. Um jedoch eine wirklich große Seite zu speichern, muss dieser Vorgang oft wiederholt werden.
Viele Unternehmen und Freelancer im Internet erledigen alles gegen Gebühr für Sie. Einer der Website-Kopierservices ist ProWebScraper. Eine Testversion ist verfügbar, mit der Sie 100 Seiten herunterladen können. Später müssen Sie natürlich bezahlen. Die Pläne beginnen bei $40 monatlich, abhängig davon, wie viele Seiten Sie scrapen möchten. Sie können immer eine andere Seite mit einer kostenlosen Testphase finden. Es ist erwähnenswert, dass einige Portale es ermöglichen zu überprüfen, ob eine bestimmte Seite kopierbar ist, da sich viele Seiten dagegen schützen.
Benutzerfreundlichere Tools für Einsteiger
Nicht jeder, der sich mit Web Scraping beschäftigen möchte, ist ein erfahrener Entwickler. Für diejenigen, die weniger technische, intuitivere Lösungen suchen, gibt es speziell dafür entwickelte Tools. Mit visuellen Oberflächen und einfachen Mechanismen ermöglichen die folgenden Programme eine effiziente Datensammlung von Websites ohne Programmierkenntnisse.
ZennoPoster
ZennoPoster ist ein Automatisierungs- und Web Scraping-Tool, das sich eher an diejenigen richtet, die keine Programmierexperten sind. Die benutzerfreundliche visuelle Oberfläche ermöglicht das Erstellen von Scraping-Skripten und anderen automatisierten Browseraufgaben.
Preis: Das Tool kostet $37 pro Monat, bietet aber eine 14-tägige Testphase.
Browser Automation Studio
BAS ist ein weiteres benutzerfreundliches Programm zur Browserautomatisierung und zum Web Scraping. Es verfügt über integrierte Skripterstellungs-Tools, mit denen Sie Daten extrahieren, Webseiten navigieren und viele weitere Funktionen ohne Programmierkenntnisse nutzen können.
Preis: Das Tool ist kostenlos.
Octoparse
Octoparse ist eine Web Scraping-Anwendung, die mühelos große Datenmengen von Websites sammelt. Die visuelle Oberfläche ermöglicht es Benutzern, die gewünschten Daten zu spezifizieren, und Octoparse übernimmt den Rest.
Preis: Eine Version dieses Tools ist kostenlos, hat aber gewisse Einschränkungen. In der kostenlosen Version können Benutzer zehn Aufgaben in ihren Konten speichern. Alle Aufgaben können nur auf lokalen Geräten mit der IP des Benutzers ausgeführt werden. Der Datenexport im kostenlosen Plan ist auf 10.000 Zeilen pro Export begrenzt, obwohl das Tool unbegrenzte Webseiten-Scans in einem Durchlauf erlaubt. Es kann auch auf beliebig vielen Geräten verwendet werden. Der technische Support ist in dieser Version jedoch eingeschränkt. Bezahlte Versionen beginnen bei $75 pro Monat.
import.io
import.io ist ein cloudbasiertes Web Scraping-Tool, das das Erstellen und Ausführen von Skripten zum Extrahieren von Daten aus Websites erleichtert. Es bietet auch Funktionen, die die gesammelten Daten automatisch strukturieren und in nützliche Formate wie Excel oder JSON umwandeln.
Preis: Das Tool bietet eine kostenlose Demo, aber die Preise für kostenpflichtige Pakete beginnen bei $399 pro Monat.
Online Web Scraping Services
Online Web Scraping funktioniert wie Parser (Komponentenanalyse-Tools), aber ihr Hauptvorteil ist die Möglichkeit, online zu arbeiten, ohne das Programm auf dem Computer herunterladen und installieren zu müssen. Das Funktionsprinzip von Websites, die Web Scraping online anbieten, ist ziemlich einfach. Wir geben die URL der gewünschten Seite ein, stellen die notwendigen Einstellungen ein (Sie können die mobile Version der Seite kopieren und alle Dateien umbenennen, das Programm speichert HTML, CSS, JavaScript, Schriftarten) und laden das Archiv herunter. Mit diesem Service kann der Webmaster jede Landingpage speichern und dann sein eigenes Format und die notwendigen Korrekturen vornehmen.
Save a Web 2 ZIP

Save a Web 2 ZIP ist die beliebteste Website für Web Scraping über einen Browser-Service. Das einfache und durchdachte Design überzeugt und alles ist völlig kostenlos. Sie müssen lediglich den Link zu der Seite angeben, die Sie kopieren möchten, die gewünschten Optionen auswählen und schon ist es fertig.
LPcopier
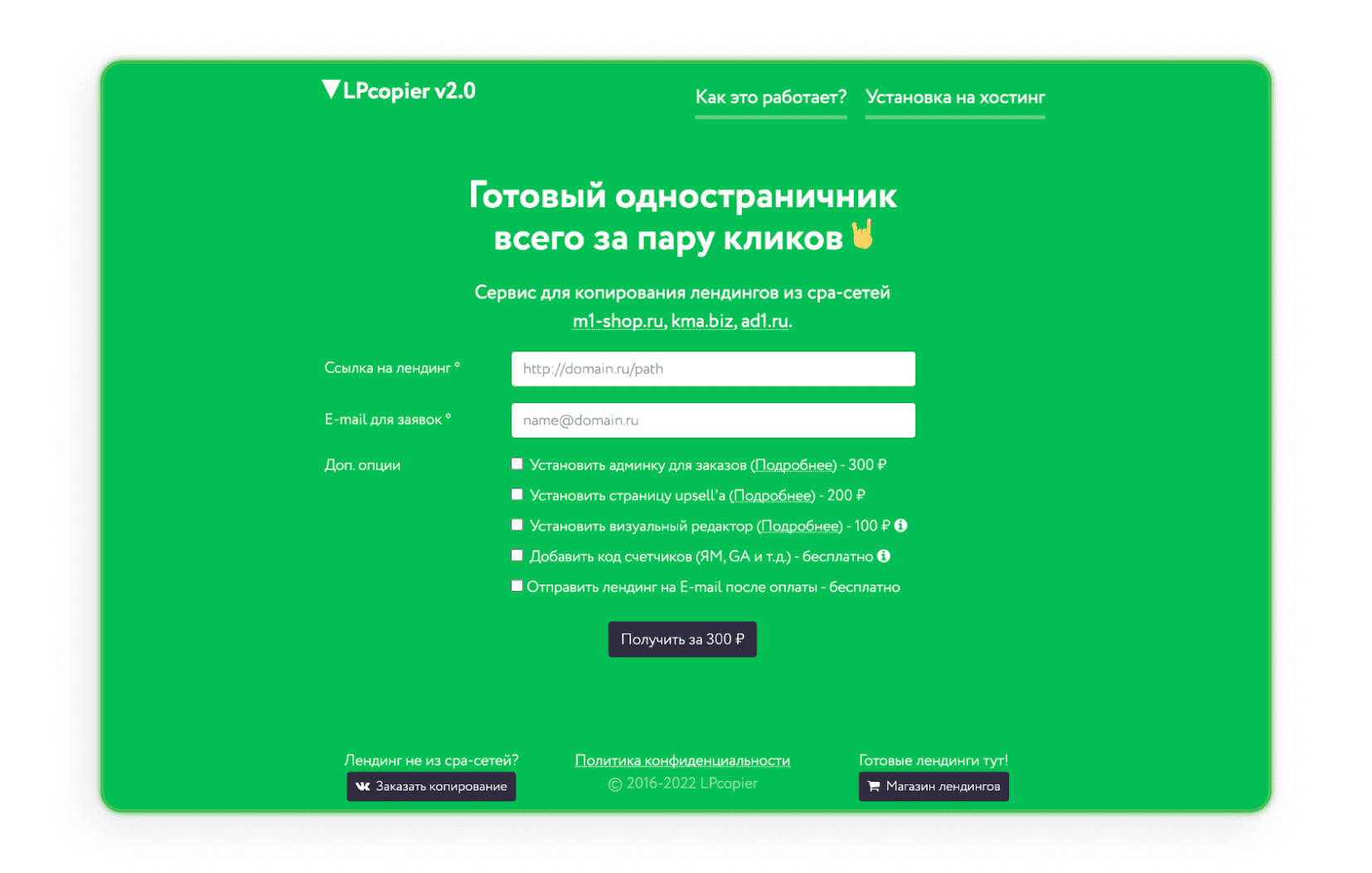
LPcopier ist ein russischer Service, der auf Affiliate Marketing abzielt. Das Portal erlaubt Scraping für etwa $5 pro Seite. Zusätzliche Dienstleistungen wie die Installation von Analysemessern werden separat berechnet. Es ist auch möglich, eine Landingpage außerhalb des CPA-Netzwerks oder eine bereits fertige Landingpage zu bestellen. Wenn Sie Russisch abschreckt, nutzen Sie einfach die von Google angebotene Übersetzungsoption.
Xdan
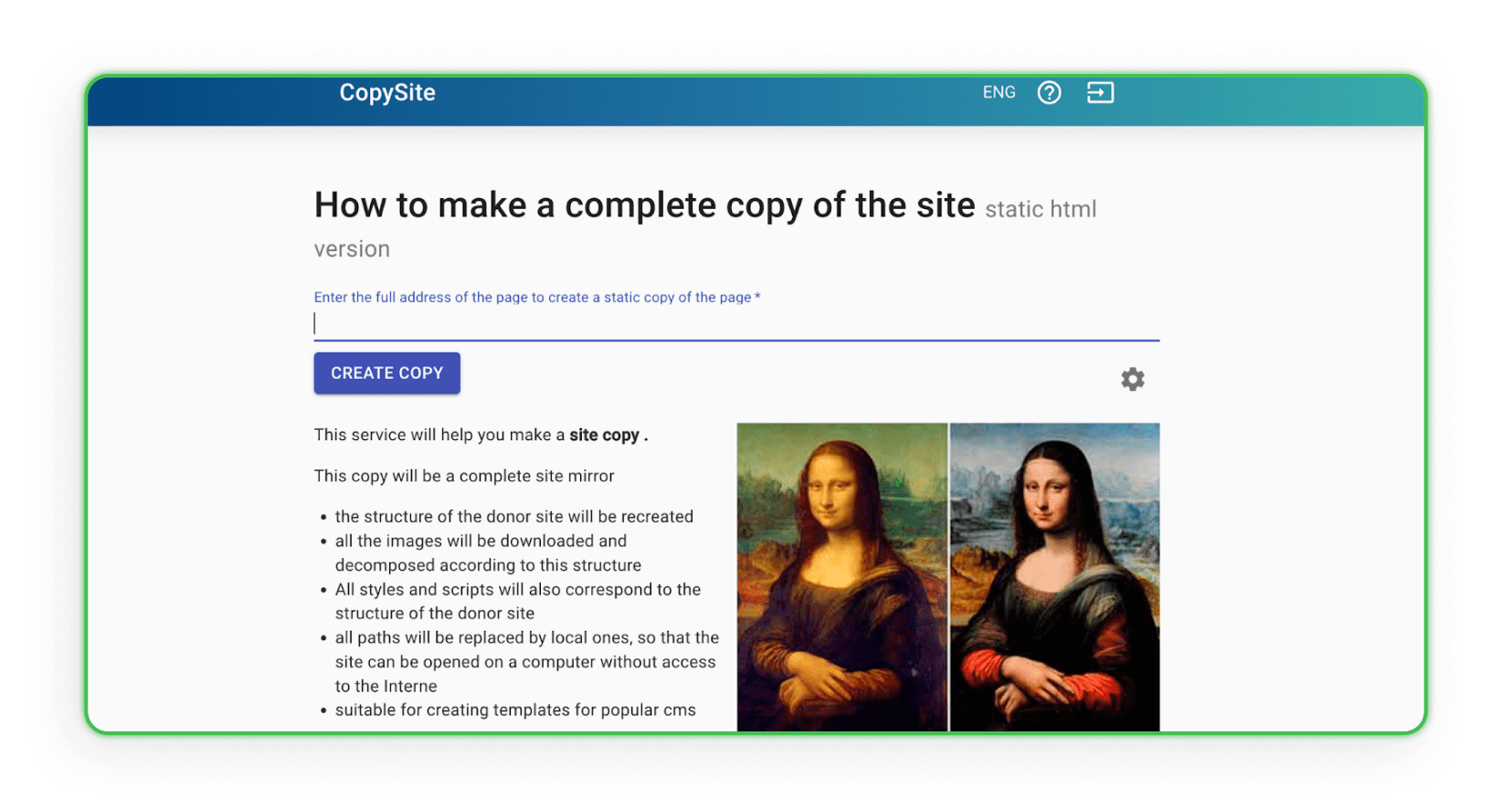
Die Xdan Website ist ebenfalls eine russische Seite (verfügbar in Englisch), die CopySite, also Web Scraping-Dienste, anbietet. Diese Website ermöglicht es, eine lokale Kopie einer Landingpage kostenlos zu erstellen und HTML-Zähler zu bereinigen oder Links bzw. Domains zu ersetzen.
Copysta

Der russische Copyst-Dienst ist einer der schnellsten Dienste dieser Art. Sie geben an, dass sie sich innerhalb von 15 Minuten melden. Das Web Scraping erfolgt über einen Link, und Sie können die Website gegen eine zusätzliche Gebühr aktualisieren lassen.
Ich habe die Website heruntergeladen. Was nun?
Haben Sie bereits eine Website heruntergeladen? Super, jetzt sollten Sie überlegen, was Sie damit machen wollen. Sicherlich möchten Sie sie ein wenig anpassen. Wie?
Wie gestalte ich die kopierte Seite um?
Um die kopierte Seite an Ihre Bedürfnisse anzupassen, müssen Sie das Asset beliebig duplizieren. Um Änderungen an der Struktur vorzunehmen, können Sie jeden Editor verwenden, der die Arbeit mit Code ermöglicht, wie Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS) oder Sublime Text. Öffnen Sie einen für Sie bequemen Editor, passen Sie den Code an, speichern Sie ihn und sehen Sie sich die Änderungen im Browser an. Bearbeiten Sie das visuelle Erscheinungsbild von HTML-Tags mit CSS, fügen Sie Webformulare, Aktionsbuttons, Links usw. hinzu. Nach dem Speichern bleibt die geänderte Datei mit den aktualisierten Funktionen, dem Layout und den zielgerichteten Aktionen auf dem Computer.
Einige Websites sammeln und analysieren alle Designdaten aus bestimmten Webarchiven, die ein Website-Erstellungs- und Verwaltungssystem (CMS) haben. Das System dupliziert das Projekt mit dem Admin und dem Speicherplatz. Archivarix ist ein Beispiel für eine solche Website (das Programm kann das Projekt wiederherstellen und archivieren).
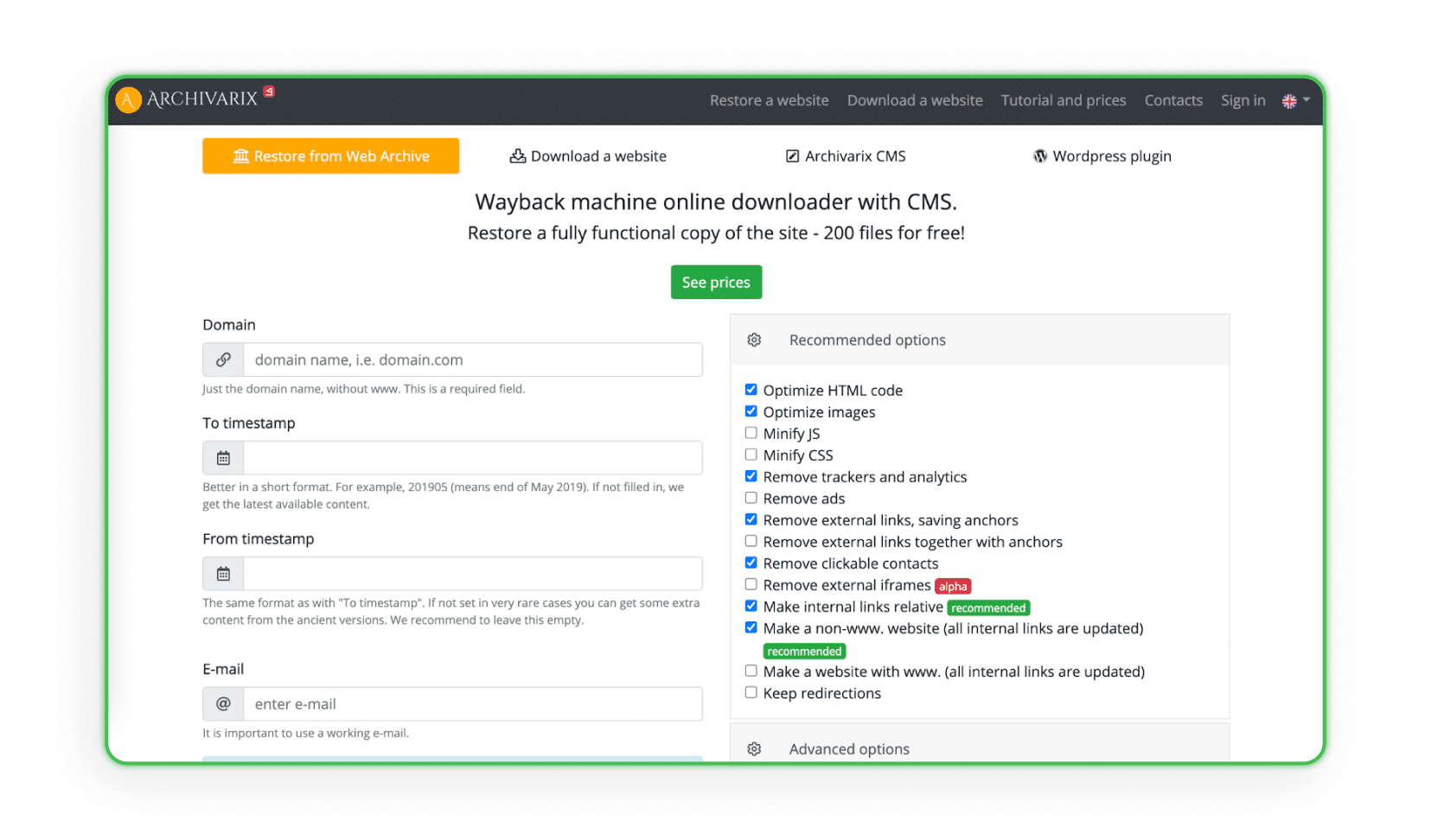
Websites auf Hosting hochladen
Der letzte und wichtigste Schritt beim Web Scraping von Landingpages ist das Hochladen auf Ihr Hosting. Denken Sie daran, dass das Kopieren und kleine visuelle Änderungen nicht ausreichen. Affiliate-Links anderer, Skripte, Ersatzpixel, JS Metrica-Codes und andere Zähler bleiben fast immer im Code der Seite. Sie müssen vor dem Hochladen auf Ihr Hosting manuell (oder mit kostenpflichtigen Programmen) entfernt werden. Wenn Sie genau wissen möchten, wie Sie Ihre Website auf das Hosting hochladen, lesen Sie unseren Artikel: „Wie erstellt man eine Landingpage? Website Schritt für Schritt erstellen“.
Wie schützt man sich vor Web Scraping?
Der Schutz vor Web Scraping ist entscheidend für die Wahrung der Privatsphäre und Sicherheit Ihrer Website und deren Daten. Sie können mehrere wirksame Methoden anwenden, um das Risiko von Web Scraping-Angriffen zu minimieren.
• Robots.txt – Die Verwendung der robots.txt-Datei ist eine Standardmethode, um mit Suchmaschinen-Robotern zu kommunizieren. Sie können angeben, welche Teile Ihrer Website durchsucht werden sollen und welche nicht. Ehrliche Bots befolgen diese Richtlinien in der Regel, aber diese Datei garantiert keinen Schutz vor allen Scraping-Bots.
• .htaccess – Über die .htaccess-Datei können Sie den Zugriff für bestimmte User Agents, die von Bots verwendet werden, blockieren. Dies ist eine Möglichkeit, unerwünschten Bots den Zugriff auf Ihre Website zu verwehren.
• CSRF (Cross-Site Request Forgery) – Der CSRF-Mechanismus kann Formulare und Interaktionen mit Ihrer Website gegen automatisches Scraping absichern. Dies kann die Verwendung von CSRF-Tokens in Formularen beinhalten.
• IP-Adressfilterung – Sie können den Zugriff auf Ihre Website auf bestimmte IP-Adressen beschränken, was helfen kann, Web Scraping-Angriffe zu minimieren.
• CAPTCHA – Das Hinzufügen von CAPTCHA zu Formularen und Interaktionen kann es Bots erschweren, automatisch mit Ihrer Website zu interagieren. Es ist eine der beliebtesten Schutzmaßnahmen gegen automatisches Scraping.
• Rate Limiting mit mod_qos auf Apache-Servern – Das Festlegen von Limits für die Anzahl der Anfragen von einer einzelnen IP-Adresse innerhalb eines bestimmten Zeitraums kann die Möglichkeit einschränken, große Datenmengen in kurzer Zeit automatisch herunterzuladen.
• Scrapshield – Der von CloudFlare angebotene Scrapshield-Dienst ist ein fortschrittliches Tool zur Erkennung und Blockierung von Web Scraping-Aktionen und kann beim Schutz Ihrer Website helfen.
Wenn Sie jemals bemerkt haben, dass Ihre Landingpage Opfer von Web Scraping-Techniken wurde, gibt es eine Möglichkeit, einen Teil des Traffics zurück auf Ihre Seite umzuleiten.
Im Afflift-Forum finden Sie einen einfachen JavaScript-Code. Platzieren Sie ihn auf Ihrer Seite, und er schützt Sie vor dem vollständigen Verlust von Traffic im Falle von Web Scraping.
Den Code finden Sie in DIESEM THREAD.
Schön, dass Sie hier sind!
Wir hoffen, Sie wissen jetzt, was Web Scraping ist, wie man eine Webseite herunterlädt und – am wichtigsten – wie man Urheberrechte einhält. Jetzt sind Sie an der Reihe, aktiv zu werden und mit dem Verdienen zu beginnen. Wenn Sie jedoch Fragen zum Affiliate Marketing haben oder nicht wissen, welches Programm Sie wählen sollen, kontaktieren Sie uns.
Haben Sie Fragen? Kontaktieren Sie uns gerne über unsere Kanäle.