
ब्लॉग / Affiliate marketing
एफिलिएट मार्केटिंग के लिए वेब स्क्रैपिंग: अपनी आवश्यकताओं के अनुसार किसी वेबसाइट को डाउनलोड करने और उसे कस्टमाइज़ करने के लिए एक गाइड।

वेब स्क्रैपिंग क्या है?
वेब स्क्रैपिंग का मतलब है वेबसाइट्स को कॉपी के रूप में कंप्यूटर पर डाउनलोड करना। यह तकनीक पूरी वेबसाइट्स को डाउनलोड करने और किसी दिए गए पोर्टल से इच्छित विशिष्ट डेटा निकालने के लिए उपयोग की जाती है। पूरा प्रोसेस बॉट्स, इंडेक्सिंग रोबोट या पायथन में लिखी गई स्क्रिप्ट के जरिए किया जाता है। यह विभिन्न प्लेटफार्मों पर उत्पाद या सेवा की समीक्षाओं के दौरान किया जाता है। इससे ग्राहक संतुष्टि स्तर और सुधार की आवश्यकता वाले क्षेत्रों से संबंधित पैटर्न की पहचान करने में मदद मिलती है। इसी दौरान, मार्केट विश्लेषण कंपनियां उत्पाद और सेवा की कीमतों, बिक्री की मात्रा और उपभोक्ता प्रवृत्तियों पर डेटा एकत्र कर सकती हैं, जिससे मूल्य निर्धारण रणनीति और मार्केटिंग योजना बनाने में मदद मिलती है।
वेब स्क्रैपिंग के कारण, विश्लेषक वेबसाइट उपयोगकर्ता व्यवहारों पर भी अध्ययन कर सकते हैं, जैसे नेविगेशन, इंटरैक्शन और व्यक्तिगत पृष्ठों पर बिताए गए समय का विश्लेषण करना। इससे यूजर इंटरफेस को अनुकूलित करने, उपयोगकर्ता अनुभव बढ़ाने और उन क्षेत्रों की पहचान करने में मदद मिल सकती है जिन्हें और सुधार की आवश्यकता है।
चिकित्सा और वैज्ञानिक अनुसंधान में, वेब स्क्रैपिंग का उपयोग वैज्ञानिक प्रकाशनों, नैदानिक परीक्षणों या चिकित्सा वेबसाइटों से डेटा एकत्र करने के लिए किया जा सकता है। इससे स्वास्थ्य प्रवृत्तियों का विश्लेषण, थेरेपी की प्रभावशीलता की जांच या खोजों की पहचान की जा सकती है।
संक्षेप में, विश्लेषण के लिए डेटा संग्रह उपकरण के रूप में वेब स्क्रैपिंग विभिन्न क्षेत्रों में घटनाओं, संबंधों और प्रवृत्तियों की गहरी समझ के द्वार खोलता है। हालांकि, यह याद रखना महत्वपूर्ण है कि वेब स्क्रैपिंग के नैतिक और कानूनी पहलुओं का पालन करें, सतर्क रहें और सार्वजनिक और निजी दोनों डेटा तक पहुंच को नियंत्रित करने वाले नियमों का पालन करें।
एफिलिएट मार्केटिंग में वेब स्क्रैपिंग
वेब स्क्रैपिंग एफिलिएट मार्केटिंग से कैसे संबंधित है? आइए सबसे महत्वपूर्ण तर्क से शुरू करें जो आपको वेब स्क्रैपिंग में रुचि लेने के लिए प्रेरित करता है, यानी प्रतिस्पर्धियों की वेबसाइट्स डाउनलोड करके बचाया गया समय। हर कोई जानता है, या कम से कम अनुमान लगाता है, कि एक अच्छा लैंडिंग पेज बनाना समय लेने वाला हो सकता है और सफलता कई बातों पर निर्भर करती है, जिनमें से एक समय भी है। अन्य कारक हैं दृष्टिकोण में बदलाव के लिए खुलापन, नई कैंपेन की खोज, परीक्षण और विज्ञापन विश्लेषण करना। वे लोग सफल होते हैं जो छोटी-छोटी बातों पर नहीं रुकते बल्कि स्केल करने के तरीके खोजते हैं। एक कैंपेन चलाने के लिए, आपको टारगेट ग्रुप, GEO चयन, ऑफ़र आदि का शोध करना होता है और सामग्री तैयार करनी होती है, जिसमें लैंडिंग पेज भी शामिल है।
कुछ लोग एफिलिएट नेटवर्क द्वारा प्रदान किए गए लैंडिंग पेज पसंद करते हैं, कुछ पेज बिल्डर्स के रेडीमेड टेम्प्लेट्स का उपयोग करते हैं, और कुछ लोग खुद से लैंडिंग पेज बनाना पसंद करते हैं। पहले दो विकल्प सबसे आम हैं। कभी-कभी, वे लाभदायक हो सकते हैं, लेकिन यह एक अल्पकालिक समाधान है क्योंकि प्रतिस्पर्धा बहुत अधिक है और उपलब्ध टेम्प्लेट्स जल्दी ही खत्म हो जाते हैं।
एक उच्च गुणवत्ता वाला लैंडिंग पेज भविष्य की सफलता और निवेश पर अच्छे रिटर्न की कुंजी है। यह जोड़ना उचित है कि हर प्रतिस्पर्धी का लैंडिंग पेज अपेक्षित परिणाम नहीं दे सकता। बेहतर यह है कि इच्छित लैंडिंग पेज को भविष्य की विज्ञापन कैंपेन के मानदंडों को ध्यान में रखते हुए ठीक से अनुकूलित किया जाए।
बेशक, आपको सब कुछ कानूनी रूप से करना याद रखना चाहिए, यानी कुछ नियमों के अनुसार, जिनके बारे में आप अभी जानेंगे।
क्या वेब स्क्रैपिंग कानूनी है?
हाँ। वेब स्क्रैपिंग निषिद्ध नहीं है; कंपनियाँ जिनसे आप अनुबंध करते हैं, वे इसे कानूनी रूप से करती हैं। दुर्भाग्य से, हमेशा कोई न कोई ऐसा होगा जो Startsool का उपयोग पायरेसी गतिविधियों के लिए करने लगेगा। वेब स्क्रैपिंग का उपयोग अनुचित मूल्य निर्धारण और कॉपीराइट सामग्री की चोरी के लिए किया जा सकता है। एक वेबसाइट मालिक जिसे स्क्रैपर द्वारा निशाना बनाया गया हो, उसे काफी वित्तीय हानि हो सकती है। दिलचस्प बात यह है कि कई विदेशी कंपनियों ने इंस्टाग्राम और फेसबुक स्टोरीज को सेव करने के लिए वेब स्क्रैपिंग का इस्तेमाल किया, जो समय-सीमित होनी चाहिए थीं।
अगर आप कॉपीराइट का सम्मान करते हैं और निर्धारित मानकों का पालन करते हैं तो स्क्रैपिंग ठीक है। हालांकि, अगर आप MyLead में स्वीकार्य न मानी जाने वाली डार्क साइड की ओर बढ़ते हैं, तो आपको विभिन्न परिणामों का सामना करना पड़ सकता है।
वेबसाइट्स को स्क्रैप करते समय कुछ अच्छी प्रथाएँ
GDPR का ध्यान रखें
ईयू देशों के संदर्भ में, आपको ईयू डेटा सुरक्षा विनियम, जिसे आमतौर पर GDPR कहा जाता है, का पालन करना चाहिए। अगर आप व्यक्तिगत डेटा स्क्रैप नहीं कर रहे हैं, तो आपको इसकी ज्यादा चिंता करने की जरूरत नहीं है। हम आपको याद दिला दें कि व्यक्तिगत डेटा ऐसा कोई भी डेटा है जिससे किसी व्यक्ति की पहचान की जा सके, उदाहरण के लिए:
• पहला और आखिरी नाम,
• ईमेल,
• फोन नंबर,
• पता,
• यूजरनेम (जैसे लॉगिन/निकनेम),
• IP पता,
• क्रेडिट या डेबिट कार्ड नंबर की जानकारी,
• चिकित्सा या बायोमेट्रिक डेटा।
वेब स्क्रैपिंग के लिए, आपको व्यक्तिगत डेटा संग्रहीत करने का कारण चाहिए। ऐसे कारणों के उदाहरण हैं:
1. वैध हित
यह साबित करना होगा कि डेटा प्रोसेसिंग व्यवसाय के लिए आवश्यक है। हालांकि, यह उन स्थितियों पर लागू नहीं होता जहां ये हित उस व्यक्ति के हितों या मौलिक अधिकारों और स्वतंत्रताओं द्वारा ओवरराइड हो जाते हैं, जिनका डेटा आप प्रोसेस करना चाहते हैं।
2. ग्राहक की सहमति
हर व्यक्ति जिसकी जानकारी आप एकत्र करना चाहते हैं, उसे आपके द्वारा बताए गए उद्देश्य के लिए उनकी जानकारी एकत्र, संग्रहीत और उपयोग करने की सहमति देनी चाहिए, जैसे मार्केटिंग उद्देश्यों के लिए।
अगर आपके पास वैध हित या ग्राहक की सहमति नहीं है, तो आप GDPR का उल्लंघन कर रहे हैं, जिससे आपको जुर्माना, स्वतंत्रता की रोक या दो साल तक की जेल हो सकती है।
ध्यान दें!
GDPR केवल यूरोपीय संघ के देशों के निवासियों पर लागू होता है, इसलिए यह संयुक्त राज्य अमेरिका, जापान या अफगानिस्तान जैसे देशों पर लागू नहीं होता।
कॉपीराइट का पालन करें
कॉपीराइट किसी भी कार्य का विशेष अधिकार है, जैसे कोई लेख, फोटो, वीडियो, संगीत का टुकड़ा आदि। आप अनुमान लगा सकते हैं कि वेब स्क्रैपिंग में कॉपीराइट बहुत महत्वपूर्ण है, क्योंकि इंटरनेट पर बहुत सा डेटा कॉपीराइटेड है। बेशक, कुछ अपवाद हैं जिनमें आप डेटा को स्क्रैप और उपयोग कर सकते हैं बिना कॉपीराइट कानूनों का उल्लंघन किए, और ये हैं:
• व्यक्तिगत सार्वजनिक उपयोग के लिए उपयोग,
• शैक्षिक या वैज्ञानिक गतिविधि के लिए उपयोग,
• उद्धरण के अधिकार के तहत उपयोग।
वेब स्क्रैपिंग - कहां से शुरू करें?
1. URL
पहला कदम है उस पेज का URL ढूंढना जिसमें आपकी रुचि है। फिर, उस विषय को निर्दिष्ट करें जिसे आप चुनना चाहते हैं। आपकी कल्पना और डेटा स्रोत ही आपकी सीमाएं हैं।
2. HTML कोड
HTML कोड की संरचना जानें। आपको HTML जानना होगा ताकि आप उस आइटम को ढूंढ सकें जिसे आप अपने प्रतिस्पर्धियों की वेबसाइट्स से डाउनलोड करना चाहते हैं। सबसे अच्छा तरीका है ब्राउज़र में उस एलिमेंट पर जाएं और Inspect विकल्प का उपयोग करें। फिर, आप HTML टैग्स देखेंगे और इच्छित कंपोनेंट की पहचान कर पाएंगे। इसका एक उदाहरण विकिपीडिया पर यहां है:
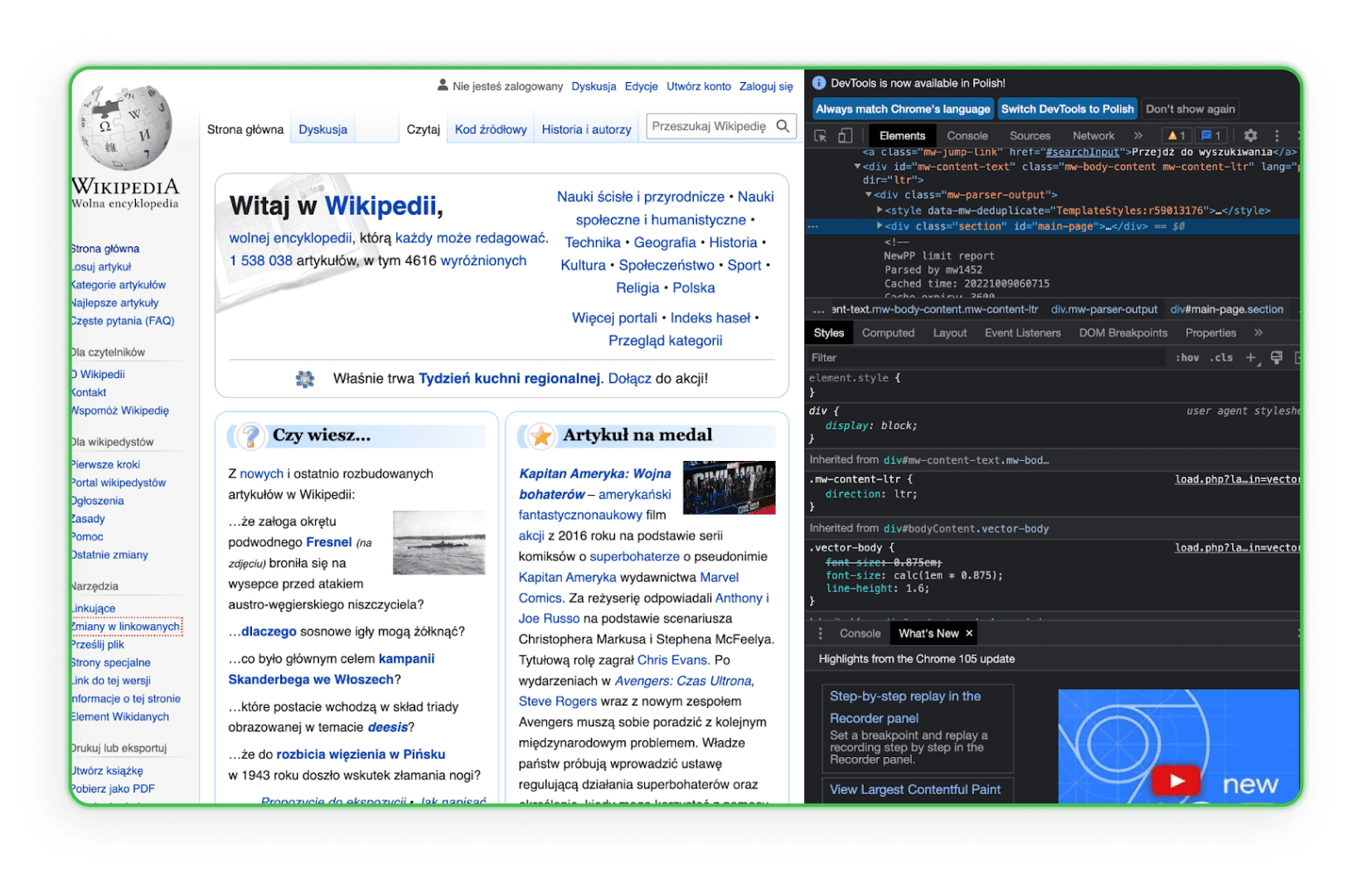
जैसा कि आप देख सकते हैं, जब आप कोड की किसी पंक्ति पर माउस ले जाते हैं, तो उस पंक्ति के कोड से संबंधित एलिमेंट पेज पर हाइलाइट हो जाता है।
3. कार्य वातावरण
आपका कार्य वातावरण तैयार होना चाहिए। आपको बाद में पता चलेगा कि आपको टेक्स्ट एडिटर्स जैसे Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS), या Sublime Text की जरूरत होगी, तो अभी से एक डाउनलोड कर लें।
वेब स्क्रैपिंग के लिए लाइब्रेरी - वेब पेज कैसे सेव करें?
वेब स्क्रैपिंग लाइब्रेरी विशिष्ट प्रोग्रामिंग भाषाओं में लिखी गई स्क्रिप्ट्स और फंक्शन्स का संगठित संग्रह हैं जो वेबसाइट्स से डेटा स्वचालित रूप से प्राप्त करने में मदद करते हैं। ये डेवलपर्स को वेब पेज के HTML या XML कोड से कंटेंट को जल्दी से विश्लेषण, फिल्टर और निकालने की अनुमति देते हैं। इनके साथ, हर फंक्शन को मैन्युअल रूप से लिखने के बजाय, डेवलपर्स वेबसाइट्स की संरचना को खोजने, नेविगेट करने और हेरफेर करने के लिए रेडीमेड, अनुकूलित समाधान का उपयोग कर सकते हैं।
Simple HTML DOM Parser - एक PHP लाइब्रेरी
यह टूल PHP डेवलपर्स के लिए है और HTML कोड के साथ हेरफेर और इंटरैक्शन को आसान बनाता है। यह HTML कोड के विशिष्ट सेक्शंस को आसानी से और सहजता से खोजने, संशोधित करने या निकालने की अनुमति देता है।
Beautiful Soup - एक Python लाइब्रेरी
Beautiful Soup एक पायथन लाइब्रेरी है जिसे HTML और XML दस्तावेजों को पार्स करने के लिए डिजाइन किया गया है। इसे DOM ट्री में आसानी से नेविगेट, खोज और संशोधित करने के लिए तैयार किया गया है, साथ ही वेब पेज से डेटा निकालने के लिए सहज इंटरफेस प्रदान करता है।
Scrapy - एक Python लाइब्रेरी
Scrapy पायथन में वेब स्क्रैपिंग के लिए एक शक्तिशाली लाइब्रेरी और फ्रेमवर्क है। यह विशेष बॉट्स बनाने में सक्षम बनाता है जो पेज को स्कैन कर सकते हैं, लिंक का अनुसरण कर सकते हैं, आवश्यक जानकारी निकाल सकते हैं और इसे वांछित फॉर्मेट्स में सहेज सकते हैं। Scrapy उन जटिल अनुप्रयोगों के लिए उपयुक्त है जिन्हें गहरी वेब पेज खोज या फॉर्म्स और अन्य पेज एलिमेंट्स के साथ इंटरैक्शन की आवश्यकता होती है।
ब्राउज़र द्वारा पेज सेव करना
कोई भी, जिसमें आप भी शामिल हैं, किसी भी ब्राउज़र में जाकर चयनित पेज को अपने कंप्यूटर पर सेव कर सकता है। यह प्रक्रिया कुछ ही मिनटों में पूरी हो जाती है और उपयोगकर्ता के कंप्यूटर पर एक HTML फाइल और फोल्डर के रूप में डुप्लिकेट पेज तैयार करती है। पूरा पेज कॉपी ब्राउज़र में खुलता है और काफी स्मूद दिखता है। हालांकि, वास्तव में बड़े पेज को सेव करने के लिए, इस प्रक्रिया को कई बार दोहराना होगा।
इंटरनेट पर कई कंपनियां और फ्रीलांसर आपके लिए सब कुछ शुल्क लेकर कर देंगे। वेबसाइट कॉपी करने की एक सेवा है ProWebScraper। एक ट्रायल वर्शन उपलब्ध है, जिससे आप 100 पेज डाउनलोड कर सकते हैं। बाद में, निश्चित रूप से, आपको भुगतान करना होगा। प्लान्स $40 प्रति माह से शुरू होते हैं, यह इस बात पर निर्भर करता है कि आप कितने पेज स्क्रैप करना चाहते हैं। आप हमेशा किसी अन्य साइट को फ्री ट्रायल पीरियड के साथ ढूंढ सकते हैं। यह उल्लेखनीय है कि कुछ पोर्टल्स आपको यह जांचने की अनुमति देते हैं कि कोई पेज कॉपी किया जा सकता है या नहीं, क्योंकि कई साइट्स खुद को इससे बचाती हैं।
शुरुआती लोगों के लिए अधिक यूजर-फ्रेंडली टूल्स
हर कोई जो वेब स्क्रैपिंग में गहराई से जाना चाहता है, वह अनुभवी डेवलपर नहीं होता। जो लोग कम तकनीकी, अधिक सहज समाधान चाहते हैं, उनके लिए विशेष रूप से उपयोग में आसान बनाए गए टूल्स हैं। विज़ुअल इंटरफेस और सरल तंत्र के साथ, निम्नलिखित सॉफ़्टवेयर कोडिंग की आवश्यकता के बिना वेबसाइट्स से डेटा कुशलतापूर्वक एकत्र करने की अनुमति देता है।
ZennoPoster
ZennoPoster एक ऑटोमेशन और वेब स्क्रैपिंग टूल है जो अधिक उन लोगों के लिए है जो जरूरी नहीं कि प्रोग्रामिंग विशेषज्ञ हों। इसका यूजर-फ्रेंडली विज़ुअल इंटरफेस स्क्रैपिंग स्क्रिप्ट्स और अन्य स्वचालित ब्राउज़र कार्यों को बनाने की अनुमति देता है।
मूल्य: यह टूल $37 प्रति माह है, लेकिन इसमें 14 दिन का ट्रायल पीरियड है।
Browser Automation Studio
BAS एक और यूजर-फ्रेंडली ब्राउज़र ऑटोमेशन और वेब स्क्रैपिंग प्रोग्राम है। इसमें बिल्ट-इन स्क्रिप्ट निर्माण टूल्स हैं जो डेटा एक्सट्रैक्शन, वेबपेज नेविगेशन और कई अन्य कार्यों की अनुमति देते हैं, बिना किसी प्रोग्रामिंग ज्ञान के।
मूल्य: यह टूल मुफ्त है।
Octoparse
Octoparse एक वेब स्क्रैपिंग एप्लिकेशन है जो वेबसाइट्स से बड़ी मात्रा में डेटा आसानी से एकत्र करता है। इसका विज़ुअल इंटरफेस उपयोगकर्ताओं को यह निर्दिष्ट करने की अनुमति देता है कि वे कौन सा डेटा एकत्र करना चाहते हैं, और बाकी काम Octoparse करता है।
मूल्य: इस टूल का एक वर्शन मुफ्त है, लेकिन इसमें कुछ सीमाएँ हैं। मुफ्त वर्शन में, उपयोगकर्ता अपने खातों में दस कार्य स्टोर कर सकते हैं। सभी कार्य केवल स्थानीय डिवाइस पर उपयोगकर्ता के IP के साथ चलाए जा सकते हैं। मुफ्त प्लान में डेटा एक्सपोर्ट प्रति एक्सपोर्ट 10,000 पंक्तियों तक सीमित है, हालांकि टूल एक रन में असीमित वेब पेज स्कैन करने की अनुमति देता है। इसे किसी भी संख्या के डिवाइस पर भी उपयोग किया जा सकता है। हालांकि, इस वर्शन में तकनीकी सहायता सीमित है। पेड वर्शन $75 प्रति माह से शुरू होते हैं।
import.io
import.io एक क्लाउड-आधारित वेब स्क्रैपिंग टूल है जो वेबसाइट्स से डेटा निकालने के लिए स्क्रिप्ट्स बनाने और चलाने की सुविधा देता है। यह एकत्र किए गए डेटा को स्वचालित रूप से संरचित करने और Excel या JSON जैसे उपयोगी फॉर्मेट्स में बदलने की सुविधाएँ भी प्रदान करता है।
मूल्य: टूल एक मुफ्त डेमो देता है, लेकिन पेड पैकेज की कीमतें $399 प्रति माह से शुरू होती हैं।
ऑनलाइन वेब स्क्रैपिंग सेवाएँ
ऑनलाइन वेब स्क्रैपिंग पार्सर्स (घटक विश्लेषक) की तरह काम करती है, लेकिन इसका मुख्य लाभ ऑनलाइन काम करने की क्षमता है, बिना प्रोग्राम को अपने कंप्यूटर पर डाउनलोड या इंस्टॉल किए। ऑनलाइन वेब स्क्रैपिंग प्रदान करने वाली वेबसाइट्स का संचालन सिद्धांत काफी सरल है। हम उस पेज का URL दर्ज करते हैं जिसमें हमारी रुचि है, आवश्यक सेटिंग्स सेट करते हैं (आप पेज का मोबाइल वर्शन कॉपी कर सकते हैं और सभी फाइलों का नाम बदल सकते हैं, प्रोग्राम HTML, CSS, JavaScript, फॉन्ट्स सेव करता है) और आर्काइव डाउनलोड करते हैं। इस सेवा के साथ, वेबमास्टर किसी भी लैंडिंग पेज को सेव कर सकता है, और फिर अपना खुद का फॉर्मेट और आवश्यक सुधार दर्ज कर सकता है।
Save a Web 2 ZIP

Save a Web 2 ZIP ब्राउज़र सेवा के माध्यम से वेब स्क्रैपिंग के लिए सबसे लोकप्रिय वेबसाइट है। इसका सरल और सुविचारित डिज़ाइन आकर्षक और भरोसेमंद है, और सब कुछ पूरी तरह से मुफ्त है। आपको बस उस पेज का लिंक देना है जिसे आप कॉपी करना चाहते हैं, अपनी पसंद के विकल्प चुनें और हो गया।
LPcopier
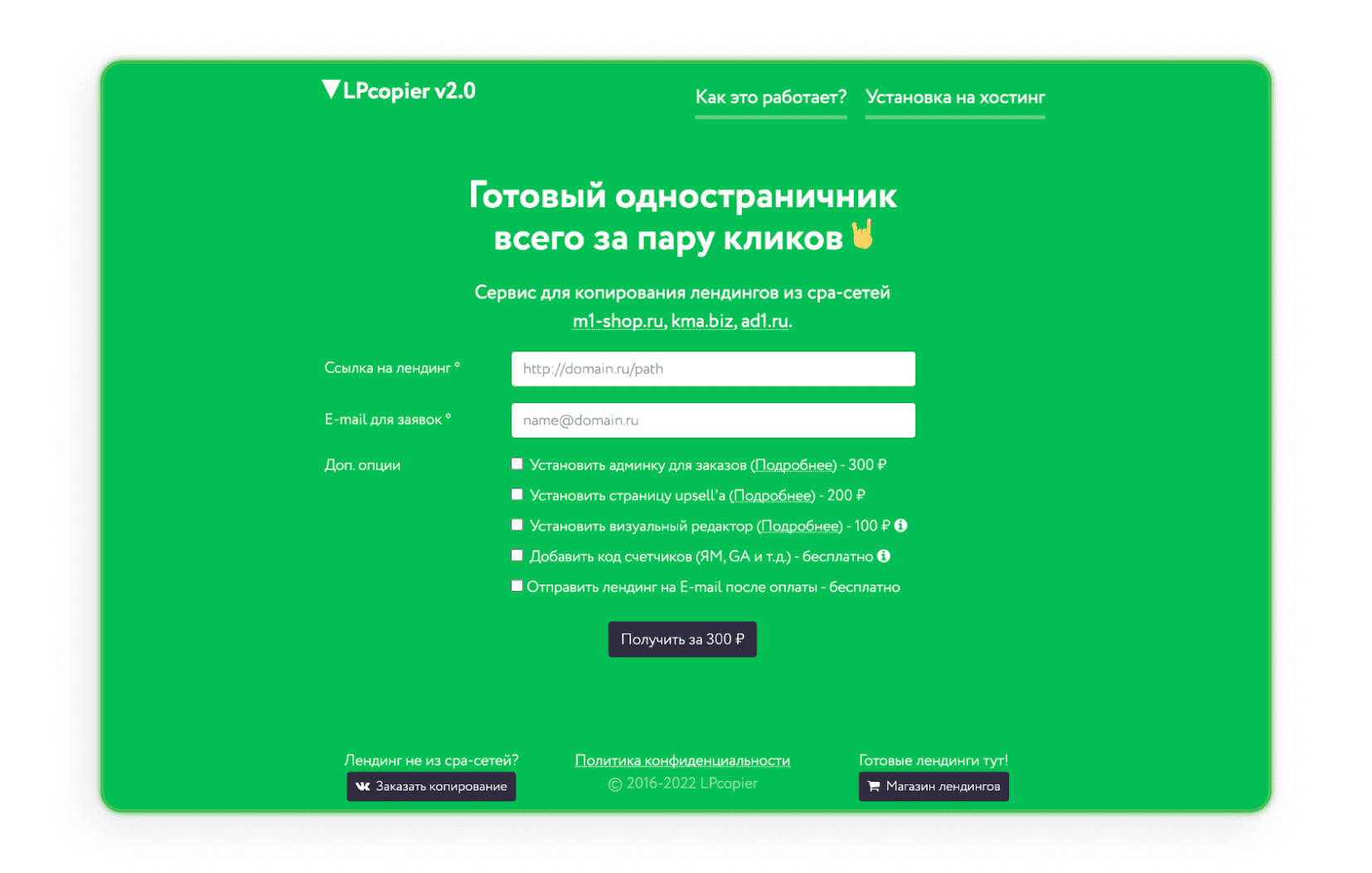
LPcopier एक रूसी सेवा है जो एफिलिएट मार्केटिंग को लक्षित करती है। पोर्टल लगभग $5 प्रति पेज के लिए स्क्रैपिंग की अनुमति देता है। अतिरिक्त सेवाएँ, जैसे विश्लेषणात्मक मीटर इंस्टॉल करना, लागत के मामले में अलग से मानी जाती हैं। CPA नेटवर्क के बाहर लैंडिंग पेज या पहले से तैयार लैंडिंग पेज का ऑर्डर देना भी संभव है। अगर आपको रूसी भाषा डराती है, तो बस Google द्वारा दी गई अनुवाद विकल्प का उपयोग करें।
Xdan
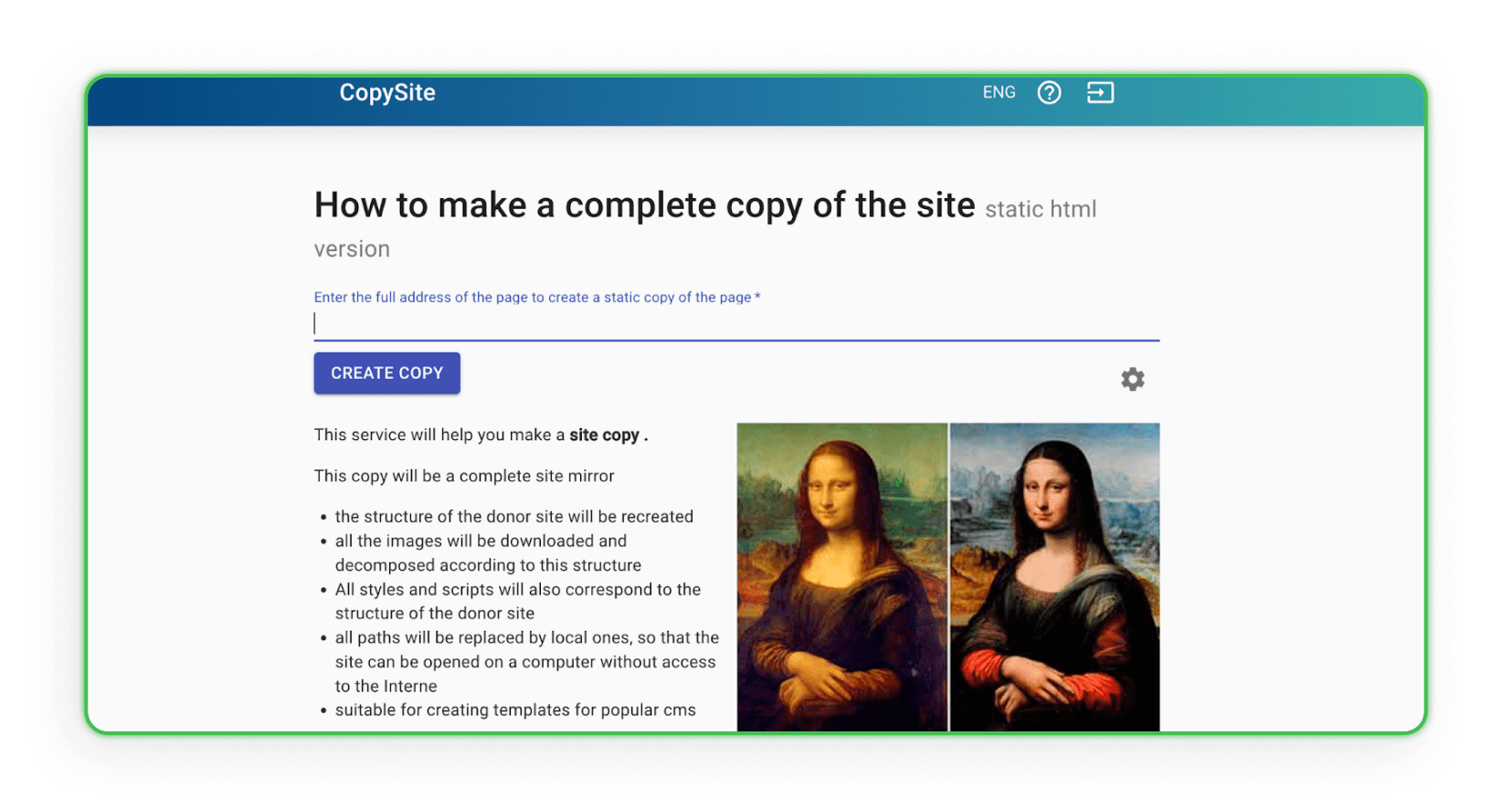
Xdan वेबसाइट भी एक रूसी वेबसाइट है (अंग्रेज़ी में उपलब्ध) जो CopySite, यानी वेब स्क्रैपिंग सेवाएँ प्रदान करती है। यह वेबसाइट आपको किसी भी लैंडिंग पेज की स्थानीय कॉपी मुफ्त में बनाने और HTML काउंटर को साफ करने या लिंक या डोमेन बदलने का विकल्प देती है।
Copysta

रूसी Copyst सेवा इस प्रकार की सबसे तेज सेवाओं में से एक है। वे घोषणा करते हैं कि वे 15 मिनट के भीतर आपसे संपर्क करेंगे। वेब स्क्रैपिंग लिंक के जरिए की जाती है, और आप अतिरिक्त शुल्क देकर वेबसाइट को अपडेट भी कर सकते हैं।
मैंने वेबसाइट डाउनलोड कर ली है। अब आगे क्या?
क्या आपने पहले ही कोई वेबसाइट डाउनलोड कर ली है? बढ़िया, अब आपको सोचना होगा कि आप इसके साथ क्या करना चाहते हैं। निश्चित रूप से आप इसमें थोड़ा बहुत बदलाव करना चाहेंगे। कैसे?
कॉपी किए गए पेज का री-डिज़ाइन कैसे करें?
अपनी जरूरतों के अनुसार कॉपी किए गए पेज का री-डिज़ाइन करने के लिए, आपको एसेट को अपनी इच्छानुसार डुप्लिकेट करना होगा। संरचना में बदलाव करने के लिए, आप किसी भी ऐसे एडिटर का उपयोग कर सकते हैं जो कोड के साथ काम करने की अनुमति देता है, जैसे Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS), या Sublime Text। अपने लिए सुविधाजनक एडिटर खोलें, कोड को अनुकूलित करें, फिर सेव करें और देखें कि ब्राउज़र में बदलाव कैसे दिखते हैं। HTML टैग्स की दृश्य उपस्थिति को CSS के साथ संपादित करें, वेब फॉर्म्स, एक्शन बटन, लिंक आदि जोड़ें। सेव करने के बाद, संशोधित फाइल कंप्यूटर पर अपडेटेड फंक्शन्स, लेआउट और लक्षित कार्यों के साथ बनी रहेगी।
कुछ वेबसाइट्स विशिष्ट वेब आर्काइव्स से सभी डिजाइन डेटा एकत्र और विश्लेषण करती हैं, जिनमें वेबसाइट निर्माण और प्रबंधन प्रणाली (CMS) होती है। सिस्टम प्रोजेक्ट को एडमिन और डिस्क स्पेस के साथ डुप्लिकेट करता है। Archivarix ऐसी ही एक वेबसाइट का उदाहरण है (प्रोग्राम प्रोजेक्ट को पुनर्स्थापित और आर्काइव कर सकता है)।
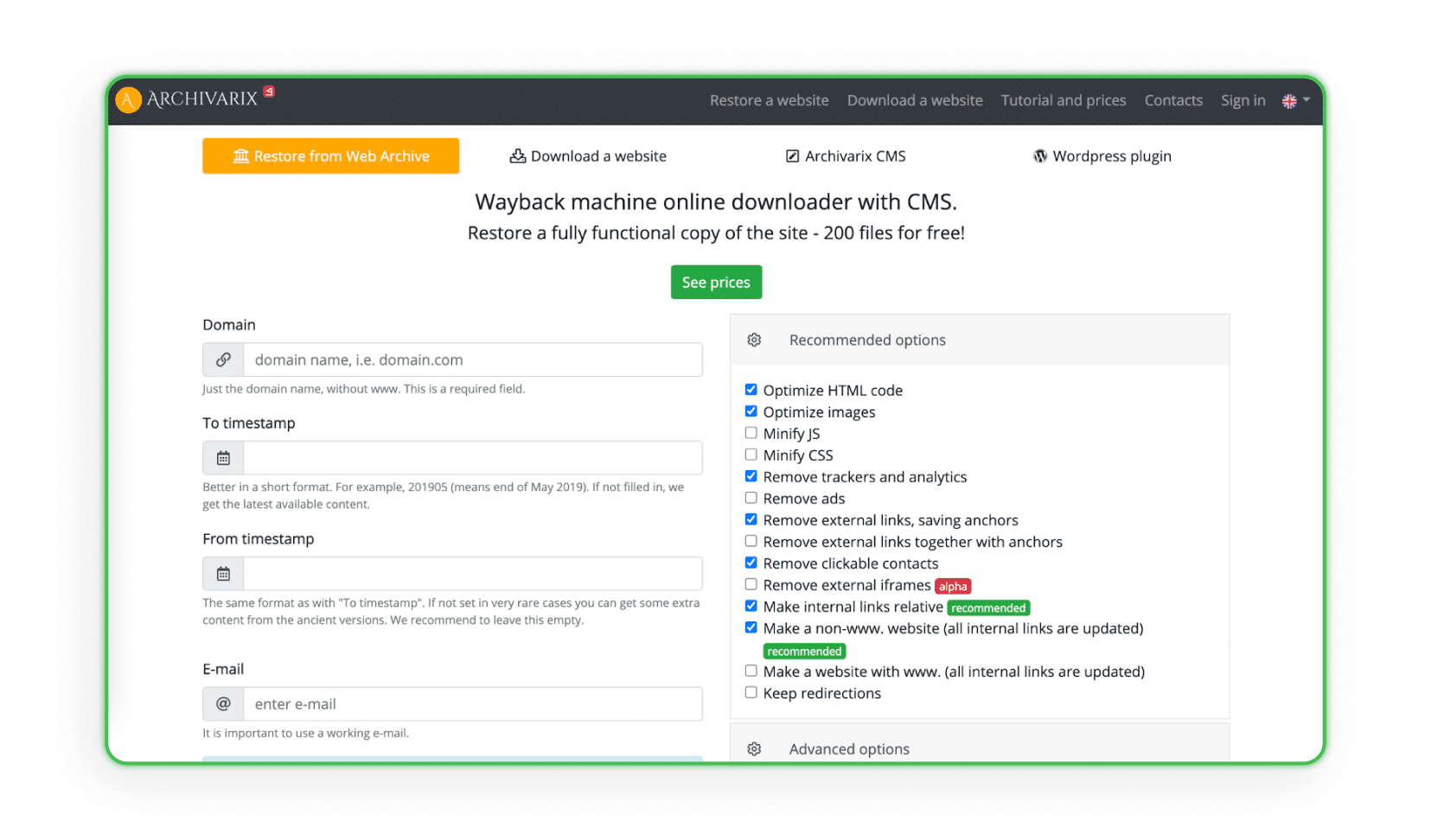
वेबसाइट्स को होस्टिंग पर अपलोड करना
लैंडिंग पेज की वेब स्क्रैपिंग में अंतिम और सबसे महत्वपूर्ण कदम है उन्हें अपनी होस्टिंग पर अपलोड करना। याद रखें कि केवल कॉपी करना और छोटे दृश्यात्मक बदलाव करना पर्याप्त नहीं है। दूसरों के एफिलिएट लिंक, स्क्रिप्ट्स, रिप्लेसमेंट पिक्सल, JS Metrica कोड्स और अन्य काउंटर लगभग हमेशा पेज के कोड में रह जाते हैं। इन्हें होस्टिंग पर अपलोड करने से पहले मैन्युअल रूप से (या पेड प्रोग्राम्स के साथ) हटाना होगा। अगर आप जानना चाहते हैं कि अपनी वेबसाइट को होस्टिंग पर कैसे अपलोड करें, तो हमारा लेख देखें: “लैंडिंग पेज कैसे बनाएं? वेबसाइट स्टेप बाय स्टेप बनाना”।
वेब स्क्रैपिंग से बचाव कैसे करें?
वेब स्क्रैपिंग से सुरक्षा आपकी वेबसाइट और उसके डेटा की गोपनीयता और सुरक्षा बनाए रखने के लिए आवश्यक है। आप वेब स्क्रैपिंग हमलों के जोखिम को कम करने के लिए कई प्रभावी तरीके अपना सकते हैं।
• Robots.txt - Robots.txt फ़ाइल का उपयोग सर्च रोबोट्स के साथ संवाद करने का एक मानक तरीका है। आप निर्दिष्ट कर सकते हैं कि आपकी साइट के कौन से हिस्से खोजे जाएं और कौन से नहीं। हालांकि ईमानदार बॉट्स आमतौर पर इन दिशानिर्देशों का पालन करते हैं, यह ध्यान देने योग्य है कि यह फ़ाइल सभी स्क्रैपिंग बॉट्स से सुरक्षा की गारंटी नहीं देती।
• .htaccess - .htaccess फ़ाइल के माध्यम से, आप उन विशिष्ट User Agents के लिए एक्सेस ब्लॉक कर सकते हैं, जिनका उपयोग बॉट्स कर सकते हैं। यह आपकी वेबसाइट को अनचाहे बॉट्स से बचाने का एक तरीका है।/li>
• CSRF (Cross-Site Request Forgery) - CSRF मैकेनिज्म आपकी साइट के फॉर्म्स और इंटरैक्शन को ऑटोमेटिक स्क्रैपिंग से सुरक्षित कर सकता है। इसमें फॉर्म्स में CSRF टोकन का उपयोग करना शामिल हो सकता है।/li>
• IP Address Filtering - आप अपनी वेबसाइट तक पहुंच केवल विशिष्ट IP पतों तक सीमित कर सकते हैं, जो वेब स्क्रैपिंग हमलों को कम करने में मदद कर सकता है।
• CAPTCHA - फॉर्म्स और इंटरैक्शन में CAPTCHA जोड़ना बॉट्स के लिए आपकी साइट के साथ स्वचालित रूप से इंटरैक्ट करना मुश्किल बना सकता है। यह ऑटोमेटिक स्क्रैपिंग के खिलाफ सबसे लोकप्रिय रक्षा में से एक है।/li>
• mod_qos के साथ Apache सर्वरों पर Rate Limiting - निर्दिष्ट समय के भीतर एक IP पते से अनुरोधों की संख्या के लिए सीमाएँ निर्धारित करना कम समय में बड़ी मात्रा में डेटा को स्वचालित रूप से डाउनलोड करने की संभावना को सीमित कर सकता है।/li>
• Scrapshield - CloudFlare द्वारा पेश किया गया Scrapshield सेवा वेब स्क्रैपिंग क्रियाओं का पता लगाने और ब्लॉक करने के लिए एक उन्नत टूल है, जो आपकी साइट की सुरक्षा में मदद कर सकता है।/li>
अगर आपने कभी देखा है कि आपका लैंडिंग पेज वेब स्क्रैपिंग तकनीकों का शिकार हुआ है, तो कुछ ट्रैफिक को वापस अपने पेज पर रीडायरेक्ट करने का तरीका है।
Afflift फोरम पर आपको एक सरल JavaScript कोड मिलेगा। इसे अपने पेज पर रखें, और यह वेब स्क्रैपिंग के मामले में आपको ट्रैफिक की पूरी हानि से बचाएगा।
कोड यहां पाया जा सकता है इस थ्रेड में।
यहाँ आपको देखकर अच्छा लगा!
हमें उम्मीद है कि अब आप जानते हैं कि वेब स्क्रैपिंग क्या है, वेब पेज कैसे डाउनलोड करें, और सबसे महत्वपूर्ण बात, कॉपीराइट कानूनों का पालन कैसे करें। अब आपकी बारी है कि आप आगे बढ़ें और कमाना शुरू करें। हालांकि, अगर आपके पास एफिलिएट मार्केटिंग के बारे में सवाल हैं या आपको नहीं पता कि कौन सा प्रोग्राम चुनना है, तो कृपया हमसे संपर्क करें।
कोई सवाल है? हमारी चैनलों के माध्यम से बेझिझक हमसे संपर्क करें।