
Blog / Affiliate marketing
Web scraping para marketing de afiliados: um guia sobre como baixar e personalizar um site para atender às suas necessidades.

O que é web scraping?
Web scraping significa baixar sites como cópias para um computador. Esta tecnologia é usada para baixar sites inteiros e extrair dados específicos de interesse de um determinado portal. Todo o processo é realizado usando bots, um robô de indexação ou um script escrito em Python. Durante avaliações de produtos ou serviços em várias plataformas, isso ajuda a identificar padrões relacionados aos níveis de satisfação do cliente e áreas que precisam de melhorias. Enquanto isso, empresas de análise de mercado podem coletar dados sobre preços de produtos e serviços, volumes de vendas e tendências de consumo, auxiliando na formulação de estratégias de preços e planejamento de ações de marketing.
Graças ao web scraping, analistas também podem realizar estudos sobre o comportamento dos usuários em sites, analisando aspectos como navegação, interações e tempo gasto em páginas individuais. Isso pode ajudar a otimizar a interface do usuário, melhorar a experiência do usuário e identificar áreas que requerem ajustes adicionais.
Na medicina e na pesquisa científica, o web scraping pode coletar dados de publicações científicas, ensaios clínicos ou sites médicos. Isso permite a análise de tendências de saúde, a avaliação da eficácia de terapias ou a identificação de descobertas.
Resumindo, o web scraping como ferramenta de coleta de dados para análise abre portas para uma compreensão mais profunda de fenômenos, relações e tendências em vários campos. No entanto, é fundamental lembrar dos aspectos éticos e legais do web scraping, agir com cautela e seguir as regras que regem o acesso a dados públicos e privados.
Web scraping no marketing de afiliados
Como o web scraping se relaciona com o marketing de afiliados? Vamos começar com o argumento mais significativo que leva você a se interessar por web scraping, ou seja, o tempo economizado ao baixar sites de concorrentes. Todo mundo sabe, ou pelo menos imagina, que criar uma boa landing page pode ser demorado e que o sucesso depende, entre outras coisas, do tempo. Outros fatores são a abertura para mudanças de abordagem, busca por novas campanhas, realização de testes e análise de publicidade. O sucesso é alcançado por quem não se prende a detalhes, mas procura maneiras de escalar. Para rodar uma campanha, você precisa pesquisar o grupo-alvo, selecionar GEO, ofertas etc., e preparar materiais, incluindo uma landing page.
Algumas pessoas preferem landing pages fornecidas pela rede de afiliados, outras usam modelos prontos de construtores de páginas e outras ainda optam por criar uma landing page do zero. As duas primeiras opções são as mais comuns. Às vezes, podem ser lucrativas, mas essa é uma solução de curto prazo, pois a concorrência é acirrada e os pacotes com modelos disponíveis se esgotam rapidamente.
Uma landing page de alta qualidade é a chave para o sucesso futuro e um bom retorno sobre o investimento. Vale acrescentar que nem todas as landing pages de um concorrente podem trazer o resultado esperado. É melhor ajustar a landing page desejada, levando em consideração os critérios da futura campanha publicitária.
Claro, você deve lembrar de fazer tudo legalmente, ou seja, de acordo com certas regras, sobre as quais você aprenderá em breve.
Web scraping é legal?
Sim. Web scraping não é proibido; as empresas que você assina fazem isso legalmente. Infelizmente, sempre haverá alguém que começa a usar Startsool para atividades de pirataria. O web scraping pode ser usado para práticas de preços desleais e roubo de conteúdo protegido por direitos autorais. Um proprietário de site alvo de scraping pode sofrer perdas financeiras substanciais. Curiosamente, o web scraping foi usado por várias empresas estrangeiras para salvar stories do Instagram e Facebook que deveriam ser temporários.
O scraping é permitido se você respeitar os direitos autorais e seguir os padrões estabelecidos. No entanto, se você decidir migrar para o lado obscuro, não aceito na MyLead, poderá enfrentar várias consequências.
Boas práticas ao fazer scraping de sites
Lembre-se do GDPR
Em relação aos países da UE, você deve cumprir o regulamento de proteção de dados da UE, conhecido como GDPR. Se você não estiver raspando dados pessoais, não precisa se preocupar muito com isso. Lembrando que dados pessoais são quaisquer dados que possam identificar uma pessoa, por exemplo:
• nome e sobrenome,
• e-mail,
• número de telefone,
• endereço,
• nome de usuário (ex: login/apelido),
• endereço IP,
• informações sobre número de cartão de crédito ou débito,
• dados médicos ou biométricos.
Para fazer web scraping, você precisa de um motivo para armazenar dados pessoais. Exemplos de tais motivos incluem:
1. Interesse legítimo
É preciso provar que o processamento de dados é necessário para o negócio legítimo. No entanto, isso não se aplica a situações em que esses interesses são sobrepostos pelos interesses ou direitos e liberdades fundamentais da pessoa cujos dados você deseja processar.
2. Consentimento do cliente
Cada pessoa cujos dados você deseja coletar deve consentir com a coleta, armazenamento e uso de seus dados conforme você pretende, por exemplo, para fins de marketing.
Se você não tem interesse legítimo ou consentimento do cliente, está violando o GDPR, o que pode resultar em multa, restrição de liberdade ou prisão de até dois anos.
Atenção!
O GDPR se aplica apenas a residentes de países da União Europeia, portanto, não se aplica a países como Estados Unidos, Japão ou Afeganistão.
Cumpra os direitos autorais
Direitos autorais são o direito exclusivo a qualquer obra realizada, por exemplo, artigo, foto, vídeo, música, etc. Você pode imaginar que os direitos autorais são muito importantes no web scraping, pois muitos dados na internet são protegidos por direitos autorais. Claro, existem exceções em que você pode fazer scraping e usar dados sem violar as leis de direitos autorais, e são elas:
• uso para fins pessoais e públicos,
• uso para fins didáticos ou atividade científica,
• uso sob o direito de citação.
Web scraping - por onde começar?
1. URL
O primeiro passo é encontrar a URL da página do seu interesse. Em seguida, especifique o tema que você quer escolher. Sua imaginação e as fontes de dados são seus únicos limites.
2. Código HTML
Aprenda a estrutura do código HTML. Você precisa conhecer HTML para encontrar um elemento que deseja baixar dos sites dos concorrentes. A melhor maneira é ir até o elemento no navegador e usar a opção Inspecionar. Assim, você verá as tags HTML e poderá identificar o componente de interesse. Veja um exemplo disso na Wikipedia:
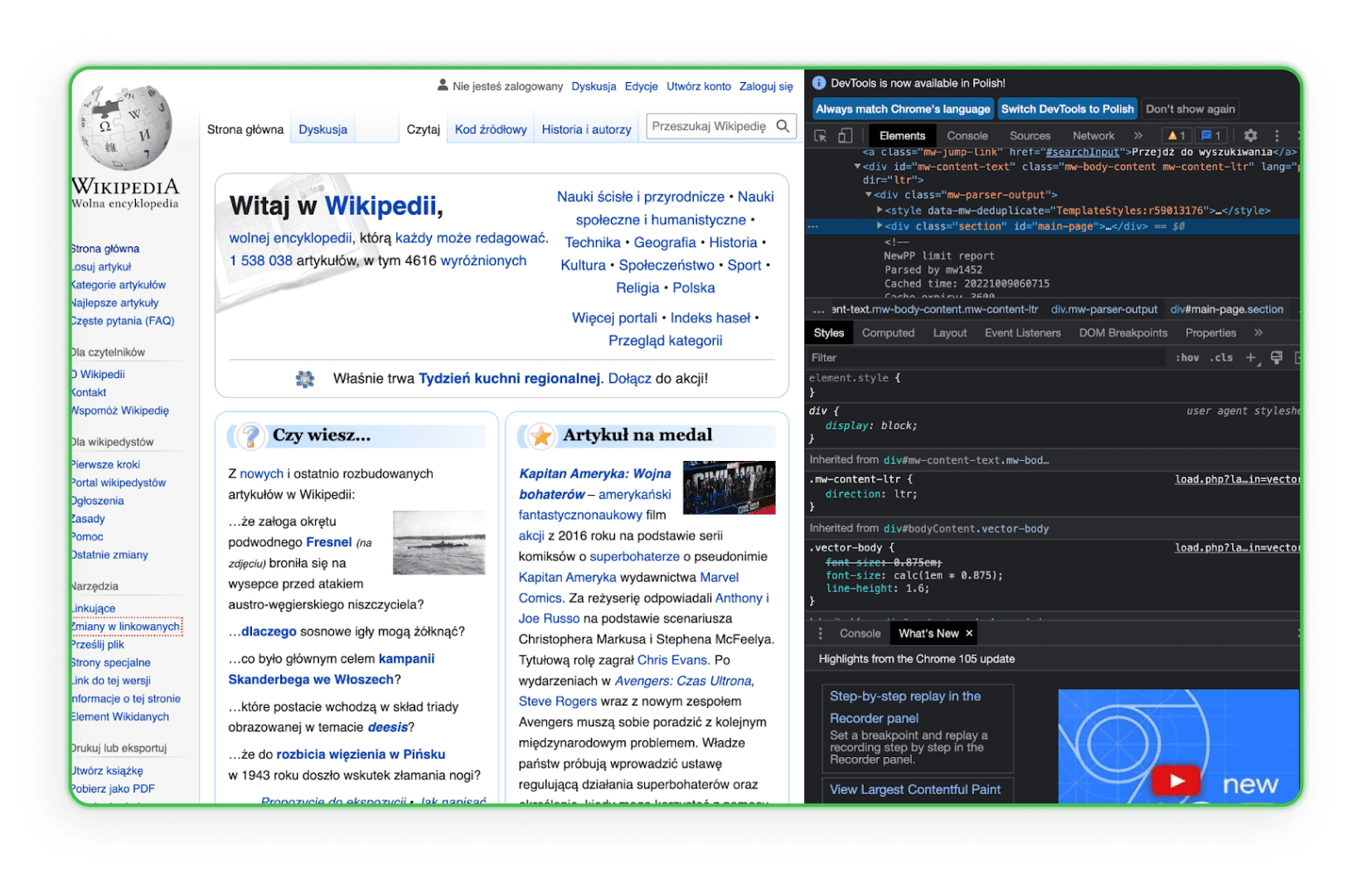
Como você pode ver, ao passar o mouse sobre uma linha de código, o elemento correspondente a essa linha é destacado na página.
3. Ambiente de trabalho
Seu ambiente de trabalho deve estar pronto. Você vai perceber depois que vai precisar de editores de texto como Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS) ou Sublime Text, então já escolha um.
Bibliotecas para web scraping - como salvar uma página web?
Bibliotecas de web scraping são coleções organizadas de scripts e funções escritas em linguagens de programação específicas que auxiliam na recuperação automática de dados de sites. Elas permitem aos desenvolvedores analisar, filtrar e extrair rapidamente conteúdos do código HTML ou XML das páginas. Com elas, ao invés de escrever cada função manualmente, os desenvolvedores podem usar soluções prontas e otimizadas para busca, navegação e manipulação da estrutura dos sites.
Simple HTML DOM Parser - Uma biblioteca PHP
Esta ferramenta é para desenvolvedores PHP e facilita a manipulação e interação com o código HTML. Permite buscar, modificar ou extrair seções específicas do código HTML de forma fácil e intuitiva.
Beautiful Soup - Uma biblioteca Python
Beautiful Soup é uma biblioteca Python projetada para analisar documentos HTML e XML. Ela foi criada para facilitar a navegação, busca e modificação da árvore DOM, fornecendo interfaces intuitivas para extração de dados de páginas web.
Scrapy - Uma biblioteca Python
Scrapy é uma poderosa biblioteca e framework para web scraping em Python. Permite criar bots especializados que podem escanear páginas, seguir links, extrair as informações necessárias e salvá-las nos formatos desejados. Scrapy é perfeito para aplicações mais complexas que exigem buscas profundas ou interação com formulários e outros elementos das páginas.
Salvando a página pelo navegador
Qualquer pessoa, inclusive você, pode salvar a página selecionada em seu computador usando qualquer navegador. Esse processo leva apenas alguns minutos e produz uma cópia da página como um arquivo HTML e uma pasta no computador do usuário. A cópia inteira da página abre no navegador e fica bastante fiel. No entanto, para salvar uma página realmente grande, esse processo precisará ser repetido várias vezes.
Muitas empresas e freelancers na Internet farão tudo isso para você mediante uma taxa. Um dos serviços de cópia de sites é o ProWebScraper. Existe uma versão de teste disponível, que permite baixar 100 páginas. Depois, claro, será necessário pagar. Os planos começam em US$ 40 mensais, dependendo de quantas páginas você deseja raspar. Você sempre pode encontrar outro site com período de teste gratuito. Vale mencionar que alguns portais permitem verificar se uma determinada página pode ser copiada, pois muitos sites se protegem contra isso.
Ferramentas mais amigáveis para iniciantes
Nem todo mundo que deseja se aprofundar em web scraping é um desenvolvedor experiente. Para quem busca soluções menos técnicas e mais intuitivas, existem ferramentas projetadas especificamente para facilidade de uso. Com interfaces visuais e mecanismos simples, os softwares a seguir permitem a coleta eficiente de dados de sites sem a necessidade de programação.
ZennoPoster
ZennoPoster é uma ferramenta de automação e web scraping voltada para quem não é necessariamente especialista em programação. Sua interface visual amigável permite criar scripts de scraping e outras tarefas automatizadas no navegador.
Preço: A ferramenta custa US$ 37 por mês, mas possui um período de teste de 14 dias.
Browser Automation Studio
BAS é outro programa amigável de automação de navegador e web scraping. Vem com ferramentas internas de criação de scripts que permitem extração de dados, navegação por páginas e várias outras funções sem qualquer conhecimento de programação.
Preço: A ferramenta é gratuita.
Octoparse
Octoparse é um aplicativo de web scraping que coleta facilmente grandes quantidades de dados de sites. Sua interface visual permite que os usuários especifiquem quais dados desejam coletar, e o Octoparse faz o resto.
Preço: Uma versão dessa ferramenta é gratuita, mas com certas restrições. Na versão gratuita, os usuários podem armazenar dez tarefas em suas contas. Todas as tarefas só podem ser executadas em dispositivos locais usando o IP do usuário. A exportação de dados no plano gratuito é limitada a 10.000 linhas por exportação, embora a ferramenta permita varreduras ilimitadas em uma única execução. Também pode ser usada em qualquer número de dispositivos. No entanto, o suporte técnico nessa versão é limitado. As versões pagas começam em US$ 75 mensais.
import.io
import.io é uma ferramenta de web scraping baseada em nuvem que facilita a criação e execução de scripts para extrair dados de sites. Também oferece recursos que estruturam automaticamente os dados coletados e os convertem em formatos úteis como Excel ou JSON.
Preço: A ferramenta oferece uma demonstração gratuita, mas os pacotes pagos começam em US$ 399 por mês.
Serviços online de web scraping
O web scraping online funciona como parsers (analisadores de componentes), mas sua principal vantagem é a capacidade de trabalhar online sem baixar e instalar o programa no seu computador. O princípio de funcionamento dos sites que oferecem web scraping online é bastante simples. Inserimos a URL da página de interesse, configuramos as opções necessárias (você pode copiar a versão mobile da página e renomear todos os arquivos, o programa salva HTML, CSS, JavaScript, fontes) e baixamos o arquivo compactado. Com esse serviço, o webmaster pode salvar qualquer landing page e depois inserir seu próprio formato e correções necessárias.
Save a Web 2 ZIP

Save a Web 2 ZIP é o site mais popular para web scraping via navegador. Seu design simples e bem pensado atrai e inspira confiança, e tudo é totalmente gratuito. Basta fornecer o link da página que deseja copiar, escolher as opções desejadas e pronto.
LPcopier
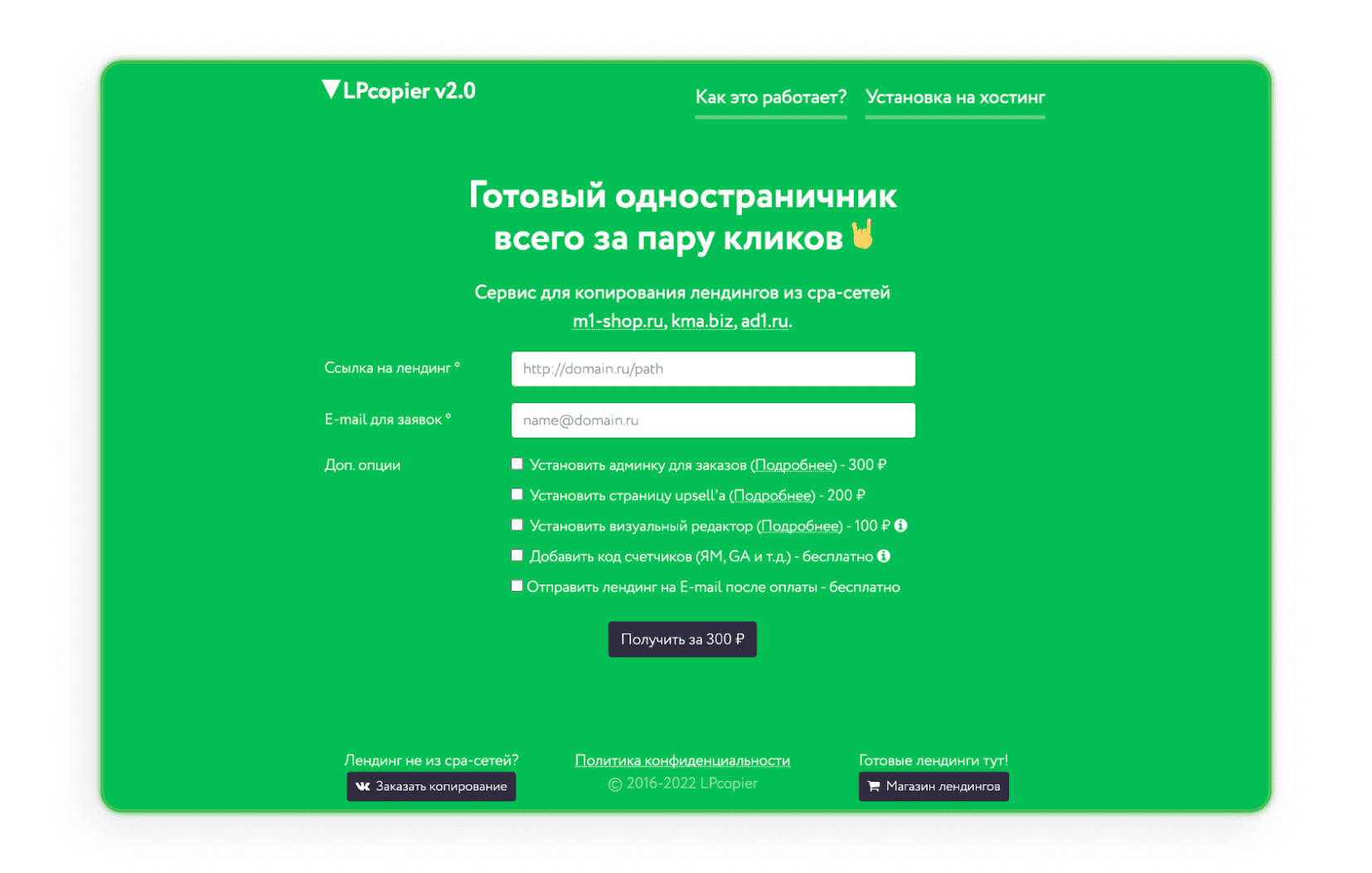
LPcopier é um serviço russo voltado para marketing de afiliados. O portal permite scraping por cerca de US$ 5 por página. Serviços adicionais, como instalação de contadores analíticos, são considerados separadamente em termos de custo. Também é possível encomendar uma landing page fora da rede CPA ou uma landing page já pronta. Se o russo assustar você, basta usar a opção de tradução que o Google oferece.
Xdan
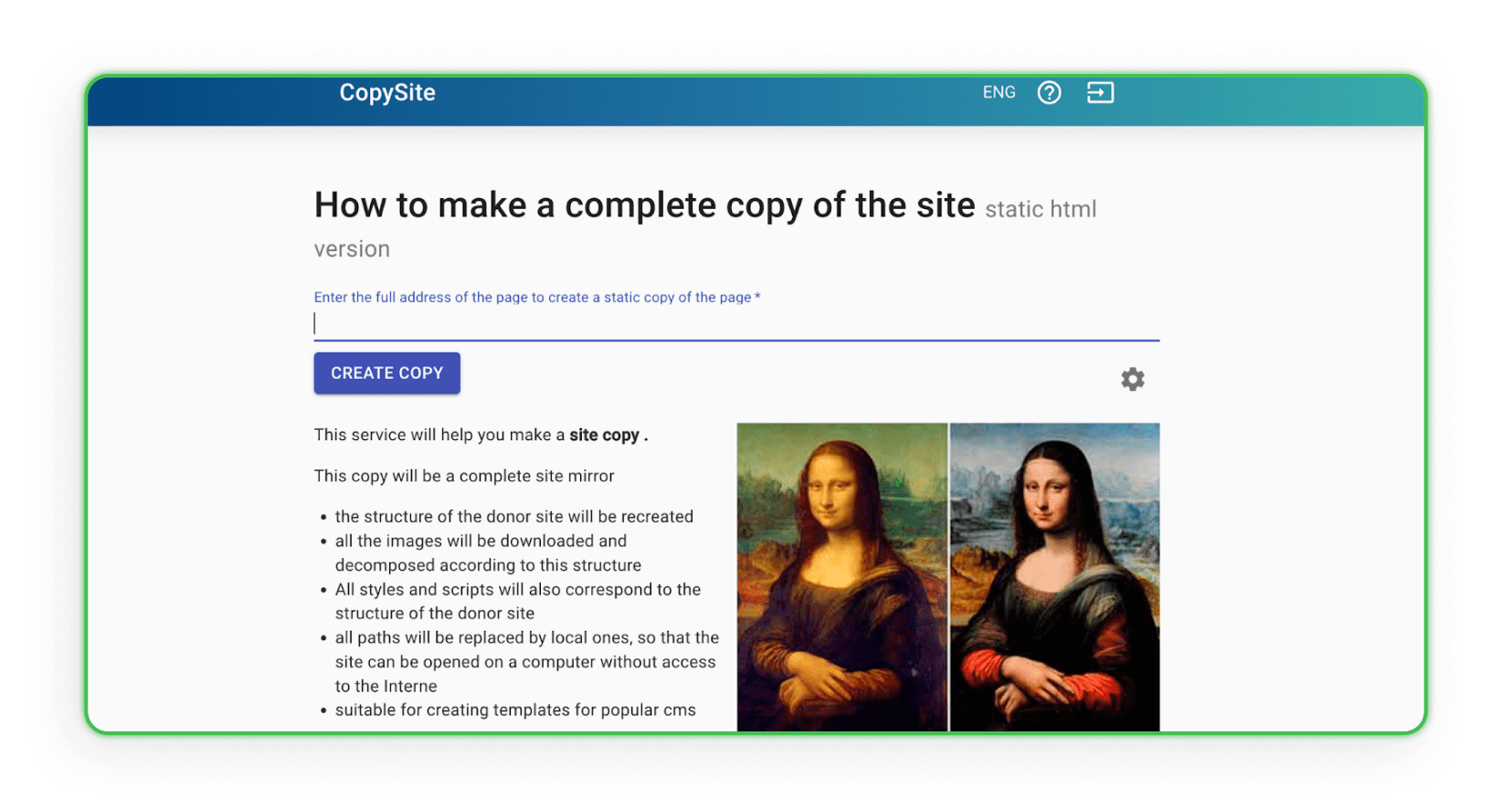
O site Xdan também é um site russo (disponível em inglês) que oferece o CopySite, ou seja, serviços de web scraping. Este site permite criar uma cópia local de uma landing page gratuitamente e escolher limpar contadores HTML ou substituir links ou domínios.
Copysta

O serviço russo Copysta é um dos serviços mais rápidos desse tipo oferecidos. Eles declaram que entrarão em contato com você em até 15 minutos. O web scraping é feito via link, e você pode atualizar o site por uma taxa adicional.
Baixei o site. E agora?
Você já baixou um site? Ótimo, agora você precisa pensar no que deseja fazer com ele. Certamente você vai querer modificá-lo um pouco. Como?
Como redesenhar a página copiada?
Para redesenhar a página copiada para suas necessidades, você precisa duplicar o material como quiser. Para fazer alterações na estrutura, você pode usar qualquer editor que permita trabalhar com código, como Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS) ou Sublime Text. Abra um editor que seja conveniente para você, personalize o código, depois salve e veja como as alterações aparecem no navegador. Edite a aparência visual das tags HTML usando CSS, adicione formulários, botões de ação, links, etc. Após salvar, o arquivo modificado permanecerá no computador com funções, layout e ações atualizadas.
Alguns sites coletam e analisam todos os dados de design de arquivos web específicos que possuem um sistema de criação e gerenciamento de sites (CMS). O sistema duplica o projeto com o admin e espaço em disco. Archivarix é um exemplo desse tipo de site (o programa pode restaurar e arquivar o projeto).
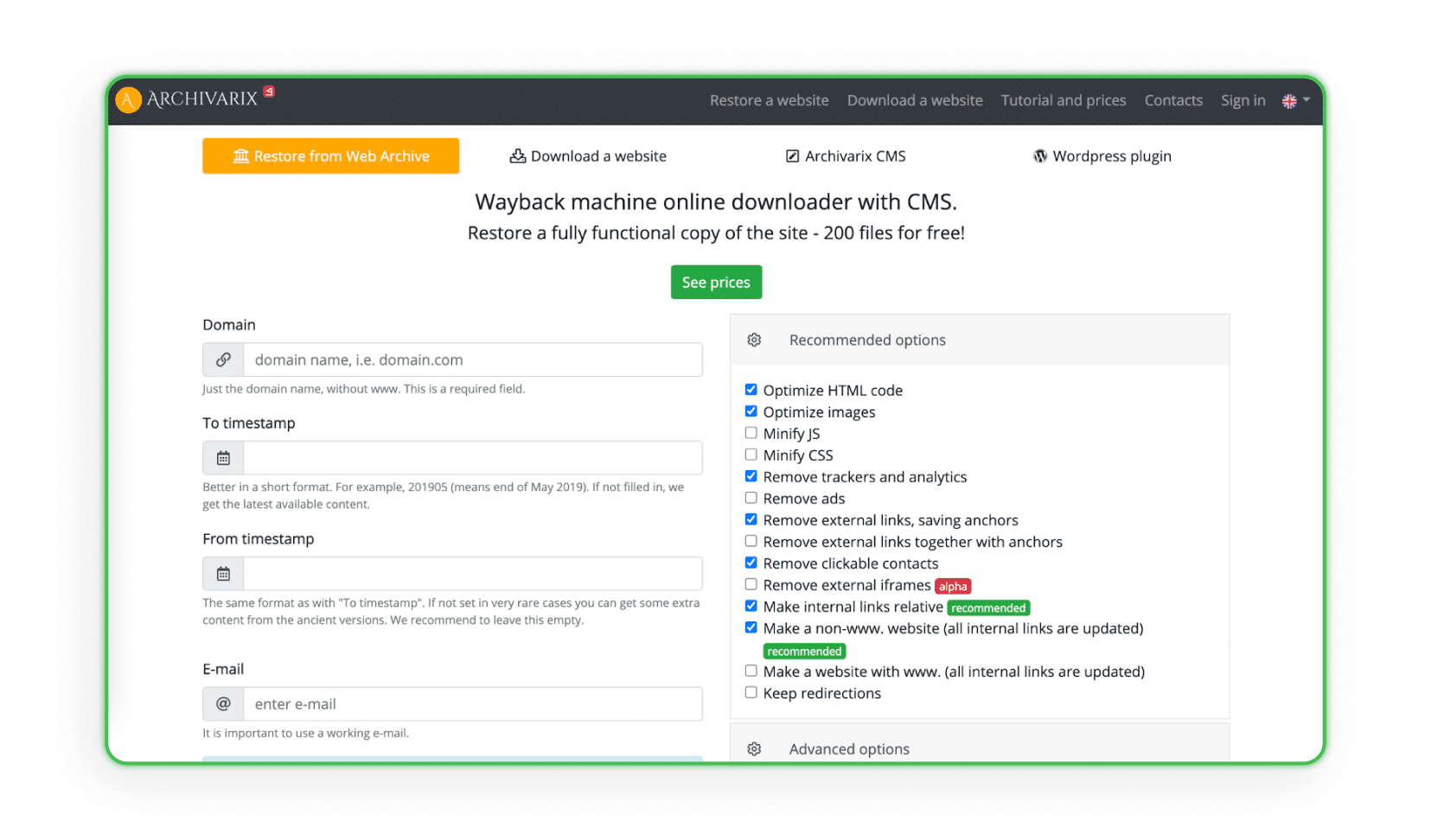
Enviando sites para a hospedagem
O último e mais importante passo do web scraping de landing pages é enviá-las para sua hospedagem. Lembre-se de que copiar e fazer pequenas alterações visuais não é suficiente. Os links de afiliados de outras pessoas, scripts, pixels de substituição, códigos JS Metrica e outros contadores quase sempre permanecem no código da página. Eles devem ser removidos manualmente (ou com programas pagos) antes de enviar para sua hospedagem. Se quiser saber exatamente como enviar seu site para a hospedagem, confira nosso artigo: “Como criar uma landing page? Criando um site passo a passo”.
Como se defender do web scraping?
A proteção contra web scraping é essencial para manter a privacidade e segurança do seu site e de seus dados. Você pode aplicar vários métodos eficazes para minimizar o risco de ataques de web scraping.
• Robots.txt - O uso do arquivo robots.txt é uma forma padrão de se comunicar com robôs de busca. Você pode especificar quais partes do seu site devem ser rastreadas e quais não devem. Embora bots honestos geralmente sigam essas diretrizes, vale notar que esse arquivo não garante proteção contra todos os bots de scraping.
• .htaccess - Por meio do arquivo .htaccess, você pode bloquear o acesso para User Agents específicos que bots possam usar. É uma maneira de evitar que bots indesejados acessem seu site./li>
• CSRF (Cross-Site Request Forgery) - O mecanismo CSRF pode proteger formulários e interações do seu site contra scraping automático. Isso pode envolver o uso de tokens CSRF em formulários./li>
• Filtragem por endereço IP - Você pode limitar o acesso ao seu site apenas a endereços IP específicos, o que pode ajudar a minimizar ataques de web scraping.
• CAPTCHA - Adicionar CAPTCHA a formulários e interações pode dificultar que bots interajam automaticamente com seu site. É uma das defesas mais populares contra scraping automático./li>
• Limitação de taxa com mod_qos em servidores Apache - Definir limites para o número de solicitações de um único endereço IP em um determinado tempo pode limitar a possibilidade de baixar grandes volumes de dados automaticamente em pouco tempo./li>
• Scrapshield - O serviço Scrapshield oferecido pela CloudFlare é uma ferramenta avançada para detectar e bloquear ações de web scraping, o que pode ajudar na proteção do seu site./li>
Se você já percebeu que sua landing page foi vítima de técnicas de web scraping, existe uma forma de redirecionar parte do tráfego de volta para sua página.
No fórum Afflift, você encontrará um código JavaScript simples. Coloque-o em sua página e ele protegerá você contra a perda total de tráfego em caso de web scraping.
O código pode ser encontrado NESTE TÓPICO.
Que bom te ver por aqui!
Esperamos que você já saiba o que é web scraping, como baixar uma página da web e, o mais importante, como cumprir as leis de direitos autorais. Agora é a sua vez de agir e começar a ganhar dinheiro. No entanto, se você tiver dúvidas sobre marketing de afiliados ou precisar saber qual programa escolher, por favor entre em contato conosco.
Tem alguma dúvida? Sinta-se à vontade para nos contatar através dos nossos canais.