
Blog / Affiliate marketing
Web scraping voor affiliate marketing: een gids voor het downloaden en aanpassen van een website aan jouw behoeften.

Wat is web scraping?
Web scraping betekent het downloaden van websites als kopieën naar een computer. Deze technologie wordt gebruikt om volledige websites te downloaden en specifieke gegevens van interesse uit een bepaald portaal te extraheren. Het hele proces wordt uitgevoerd met behulp van bots, een indexeerrobot of een script geschreven in Python. Tijdens product- of dienstbeoordelingen op verschillende platforms. Dit helpt patronen te identificeren die verband houden met klanttevredenheid en gebieden die verbetering behoeven. Ondertussen kunnen marktanalysebedrijven gegevens verzamelen over prijzen van producten en diensten, verkoopvolumes en consumententrends, wat helpt bij het formuleren van prijsstrategieën en het plannen van marketingacties.
Dankzij web scraping kunnen analisten ook onderzoeken uitvoeren naar het gedrag van websitegebruikers, waarbij aspecten zoals navigatie, interacties en de tijd die op afzonderlijke pagina's wordt doorgebracht, worden geanalyseerd. Dit kan helpen bij het optimaliseren van de gebruikersinterface, het verbeteren van de gebruikerservaring en het identificeren van gebieden die verdere verfijning vereisen.
In de geneeskunde en wetenschappelijk onderzoek kan web scraping gegevens verzamelen uit wetenschappelijke publicaties, klinische proeven of medische websites. Dit maakt het mogelijk om gezondheidstrends te analyseren, de effectiviteit van therapieën te onderzoeken of ontdekkingen te identificeren.
Samengevat opent web scraping als hulpmiddel voor het verzamelen van gegevens voor analyse de deur naar een dieper begrip van fenomenen, relaties en trends in verschillende vakgebieden. Het is echter cruciaal om de ethische en juridische aspecten van web scraping in gedachten te houden, voorzichtig te zijn en de regels na te leven die de toegang tot zowel publieke als private gegevens reguleren.
Web scraping in affiliate marketing
Hoe verhoudt web scraping zich tot affiliate marketing? Laten we beginnen met het belangrijkste argument dat je zou moeten aanzetten om geïnteresseerd te raken in web scraping, namelijk de tijdwinst die je behaalt door websites van concurrenten te downloaden. Iedereen weet, of vermoedt op zijn minst, dat het maken van een goede landingspagina tijdrovend kan zijn en dat succes onder andere afhankelijk is van tijd. Andere factoren zijn openstaan voor een andere aanpak, zoeken naar nieuwe campagnes, het uitvoeren van tests en het analyseren van advertenties. Succes wordt behaald door degenen die niet bij kleinigheden blijven steken, maar zoeken naar manieren om te schalen. Om één campagne te draaien, moet je onderzoek doen naar de doelgroep, GEO-selectie, aanbiedingen, enz., en materialen voorbereiden, waaronder een landingspagina.
Sommige mensen geven de voorkeur aan landingspagina's die door het affiliate netwerk worden geleverd, anderen gebruiken kant-en-klare sjablonen van paginabouwers, en weer anderen kiezen ervoor om een landingspagina helemaal zelf te maken. De eerste twee opties komen het meest voor. Soms kunnen ze winstgevend zijn, maar dit is een kortetermijnoplossing omdat de concurrentie hevig is en pakketten met beschikbare sjablonen snel opraken.
Een hoogwaardige landingspagina is de sleutel tot toekomstig succes en een goed rendement op investering. Het is het vermelden waard dat niet elke landingspagina van een concurrent het gewenste resultaat zal opleveren. Het is beter om de gewenste landingspagina bij te schaven, rekening houdend met de criteria van de toekomstige advertentiecampagne.
Natuurlijk moet je alles legaal doen, dus volgens bepaalde regels, waar je zo meteen meer over leert.
Is web scraping legaal?
Ja. Web scraping is niet verboden; bedrijven waarmee je contracten sluit, doen dit legaal. Helaas zal er altijd iemand zijn die Startsool gaat gebruiken voor piraterij-activiteiten. Web scraping kan worden gebruikt voor oneerlijke prijspraktijken en het stelen van auteursrechtelijk beschermd materiaal. Een website-eigenaar die wordt gescrapet kan aanzienlijke financiële verliezen lijden. Interessant is dat web scraping door verschillende buitenlandse bedrijven werd gebruikt om Instagram- en Facebook-verhalen op te slaan die eigenlijk tijdsgebonden zouden moeten zijn.
Scraping is toegestaan zolang je het auteursrecht respecteert en je aan de vastgestelde normen houdt. Echter, als je besluit de duistere kant op te gaan die niet wordt geaccepteerd bij MyLead, kun je verschillende gevolgen ondervinden.
Enkele goede praktijken bij het scrapen van websites
Denk aan de AVG
Voor wat betreft EU-landen moet je voldoen aan de EU-regelgeving inzake gegevensbescherming, beter bekend als de AVG (GDPR). Als je geen persoonsgegevens scrapt, hoef je je daar niet al te veel zorgen over te maken. Ter herinnering: persoonsgegevens zijn alle gegevens waarmee een persoon geïdentificeerd kan worden, bijvoorbeeld:
• voor- en achternaam,
• e-mailadres,
• telefoonnummer,
• adres,
• gebruikersnaam (bijv. login/nickname),
• IP-adres,
• informatie over het creditcard- of bankpasnummer,
• medische of biometrische gegevens.
Voor web scraping heb je een reden nodig om persoonsgegevens op te slaan. Voorbeelden van zulke redenen zijn:
1. Gerechtvaardigd belang
Het moet worden aangetoond dat gegevensverwerking noodzakelijk is voor het legitieme zakelijke belang. Dit geldt echter niet als deze belangen worden overschaduwd door de belangen of fundamentele rechten en vrijheden van de persoon wiens gegevens je wilt verwerken.
2. Toestemming van de klant
Iedere persoon van wie je gegevens wilt verzamelen, moet toestemming geven voor het verzamelen, opslaan en gebruiken van hun gegevens zoals jij dat wilt, bijvoorbeeld voor marketingdoeleinden.
Als je geen gerechtvaardigd belang of toestemming van de klant hebt, overtreed je de AVG, wat kan leiden tot een boete, beperking van vrijheid of gevangenisstraf tot twee jaar.
Let op!
De AVG is alleen van toepassing op inwoners van landen van de Europese Unie, dus niet op landen zoals de Verenigde Staten, Japan of Afghanistan.
Houd je aan het auteursrecht
Auteursrecht is het exclusieve recht op elk gemaakt werk, bijvoorbeeld een artikel, foto, video, muziekstuk, enz. Je kunt wel raden dat auteursrecht heel belangrijk is bij web scraping, omdat veel gegevens op het internet auteursrechtelijk beschermd zijn. Natuurlijk zijn er uitzonderingen waarbij je gegevens mag scrapen en gebruiken zonder het auteursrecht te schenden, en dat zijn:
• gebruik voor persoonlijk openbaar gebruik,
• gebruik voor didactische of wetenschappelijke doeleinden,
• gebruik onder het citaatrecht.
Web scraping - waar begin je?
1. URL
De eerste stap is het vinden van de URL van de pagina waarin je geïnteresseerd bent. Bepaal vervolgens het onderwerp dat je wilt kiezen. Alleen je verbeelding en gegevensbronnen zijn je beperking.
2. HTML-code
Leer de structuur van de HTML-code. Je moet HTML kennen om een element te vinden dat je van de website van je concurrenten wilt downloaden. De beste manier is om naar het element in de browser te gaan en de optie Inspecteren te gebruiken. Dan zie je de HTML-tags en kun je het gewenste onderdeel identificeren. Hier is een voorbeeld hiervan op Wikipedia:
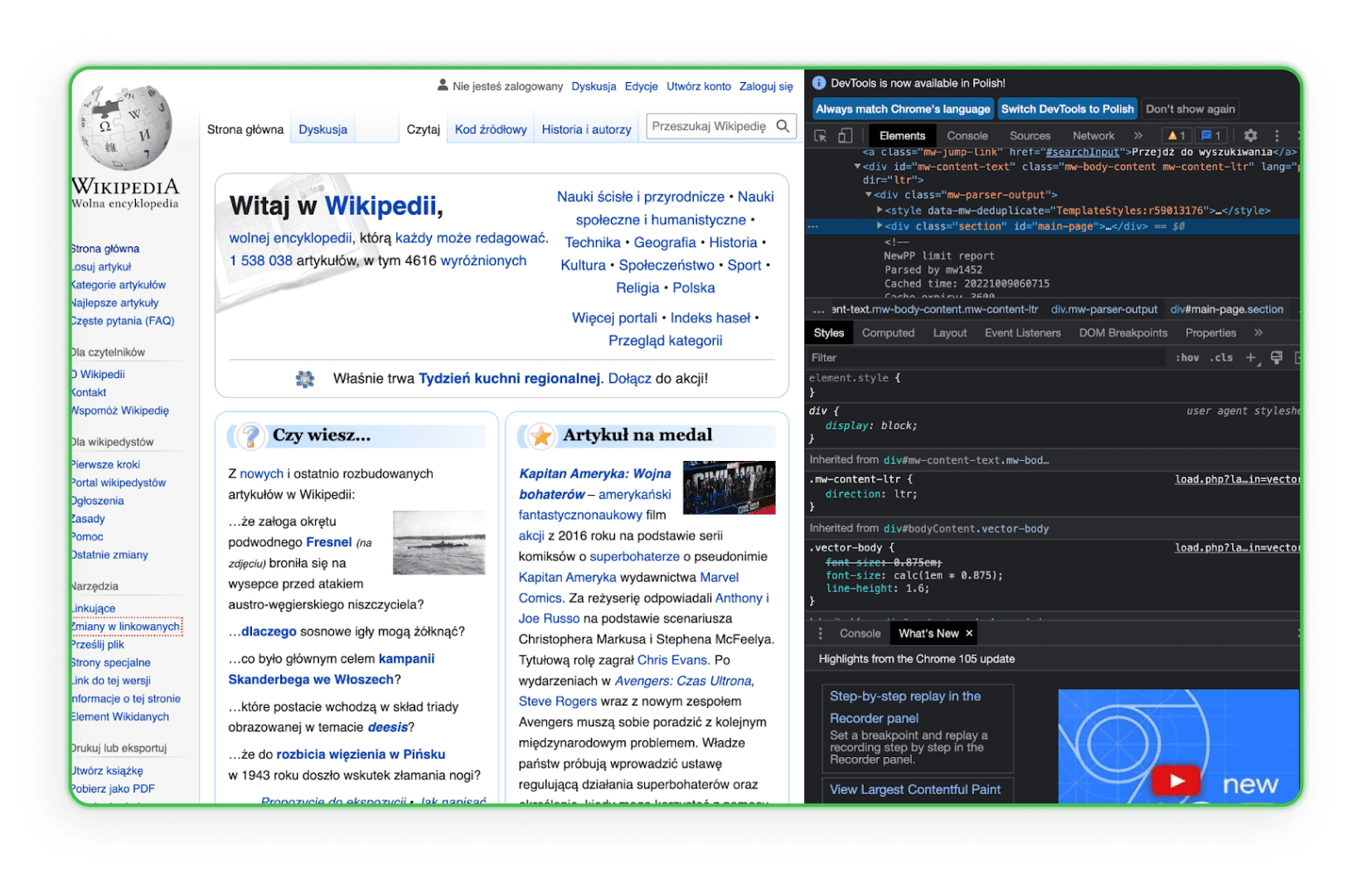
Zoals je kunt zien, wordt wanneer je met de muis over een bepaalde regel code beweegt, het element dat bij deze regel hoort op de pagina gemarkeerd.
3. Werkomgeving
Je werkomgeving moet klaar zijn. Je zult later merken dat je teksteditors nodig hebt zoals Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS), of Sublime Text, dus download er alvast één.
Bibliotheken voor web scraping - hoe sla je een webpagina op?
Web scraping-bibliotheken zijn georganiseerde collecties van scripts en functies geschreven in specifieke programmeertalen die helpen bij het automatisch ophalen van gegevens van websites. Ze stellen ontwikkelaars in staat om snel inhoud van HTML- of XML-code van webpagina's te analyseren, filteren en extraheren. Met deze bibliotheken hoeven ontwikkelaars niet elke functie handmatig te schrijven, maar kunnen ze gebruik maken van kant-en-klare, geoptimaliseerde oplossingen voor het zoeken, navigeren en manipuleren van de structuur van websites.
Simple HTML DOM Parser - Een PHP-bibliotheek
Deze tool is voor PHP-ontwikkelaars en vergemakkelijkt de manipulatie en interactie met HTML-code. Hiermee kun je gemakkelijk en intuïtief zoeken, wijzigen of specifieke delen van de HTML-code extraheren.
Beautiful Soup - Een Python-bibliotheek
Beautiful Soup is een Python-bibliotheek die is ontworpen om HTML- en XML-documenten te parseren. Het is gemaakt om eenvoudig te navigeren, te zoeken en de DOM-boom aan te passen, terwijl het intuïtieve interfaces biedt voor het extraheren van gegevens van webpagina's.
Scrapy - Een Python-bibliotheek
Scrapy is een krachtige bibliotheek en framework voor web scraping in Python. Hiermee kun je gespecialiseerde bots maken die pagina's kunnen scannen, links kunnen volgen, de benodigde informatie kunnen extraheren en deze in de gewenste formaten kunnen opslaan. Scrapy is perfect voor complexere toepassingen die diepgaand zoeken op webpagina's of interactie met formulieren en andere pagina-elementen vereisen.
De pagina opslaan via de browser
Iedereen, ook jij, kan de geselecteerde pagina op zijn computer opslaan via elke browser. Dit proces duurt slechts een paar minuten en levert een duplicaat van de pagina op als een HTML-bestand en een map op de computer van de gebruiker. De volledige kopie van de pagina wordt in de browser geopend en ziet er vrij soepel uit. Om echter een echt grote pagina op te slaan, moet dit proces vele malen worden herhaald.
Veel bedrijven en freelancers op internet doen alles voor je tegen betaling. Een van de diensten voor het kopiëren van websites is ProWebScraper. Er is een proefversie beschikbaar waarmee je 100 pagina's kunt downloaden. Daarna moet je natuurlijk betalen. De abonnementen beginnen vanaf $40 per maand, afhankelijk van hoeveel pagina's je wilt scrapen. Je kunt altijd een andere site vinden met een gratis proefperiode. Het is het vermelden waard dat sommige portalen je laten controleren of een bepaalde pagina gekopieerd kan worden, omdat veel sites zich hiertegen beschermen.
Meer gebruiksvriendelijke tools voor beginners
Niet iedereen die zich wil verdiepen in web scraping is een ervaren ontwikkelaar. Voor degenen die op zoek zijn naar minder technische, meer intuïtieve oplossingen, zijn er tools die specifiek zijn ontworpen voor gebruiksgemak. Met visuele interfaces en eenvoudige mechanismen kun je met de volgende software efficiënt gegevens verzamelen van websites zonder te hoeven programmeren.
ZennoPoster
ZennoPoster is een automatiserings- en web scraping-tool die meer gericht is op mensen die niet per se programmeerexperts zijn. De gebruiksvriendelijke visuele interface maakt het mogelijk om scraping-scripts en andere geautomatiseerde browsertaken te maken.
Prijs: De tool kost $37 per maand, maar heeft een proefperiode van 14 dagen.
Browser Automation Studio
BAS is een ander gebruiksvriendelijk programma voor browserautomatisering en web scraping. Het bevat ingebouwde tools voor het maken van scripts waarmee je gegevens kunt extraheren, door webpagina's kunt navigeren en nog veel meer zonder enige programmeerkennis.
Prijs: De tool is gratis.
Octoparse
Octoparse is een web scraping-applicatie die moeiteloos grote hoeveelheden gegevens van websites verzamelt. Dankzij de visuele interface kan de gebruiker specificeren welke gegevens hij wil verzamelen, en Octoparse doet de rest.
Prijs: Hoewel één versie van deze tool gratis is, zijn er bepaalde beperkingen. In de gratis versie kunnen gebruikers tien taken in hun account opslaan. Alle taken kunnen alleen lokaal worden uitgevoerd met het IP-adres van de gebruiker. Gegevens exporteren in het gratis plan is beperkt tot 10.000 rijen per export, hoewel de tool onbeperkt webpagina's kan scannen in één run. Het kan ook op een onbeperkt aantal apparaten worden gebruikt. Technische ondersteuning in deze versie is echter beperkt. Betaalde versies beginnen vanaf $75 per maand.
import.io
import.io is een cloudgebaseerde web scraping-tool die het maken en uitvoeren van scripts voor het extraheren van gegevens van websites mogelijk maakt. Het biedt ook functies om de verzamelde gegevens automatisch te structureren en te converteren naar bruikbare formaten zoals Excel of JSON.
Prijs: De tool biedt een gratis demo, maar de prijzen voor betaalde pakketten beginnen vanaf $399 per maand.
Online web scraping-diensten
Online web scraping werkt als parsers (componentanalysatoren), maar hun belangrijkste voordeel is dat ze online kunnen werken zonder dat je het programma op je computer hoeft te downloaden en te installeren. Het principe van de werking van websites die online web scraping aanbieden is vrij eenvoudig. Je voert de URL van de pagina in waarin je geïnteresseerd bent, stelt de nodige instellingen in (je kunt de mobiele versie van de pagina kopiëren en alle bestanden hernoemen, het programma slaat HTML, CSS, JavaScript, lettertypen op) en downloadt het archief. Met deze dienst kan de webmaster elke landingspagina opslaan en vervolgens zijn eigen formaat en noodzakelijke correcties aanbrengen.
Save a Web 2 ZIP

Save a Web 2 ZIP is de populairste website voor web scraping via een browserservice. Het eenvoudige en doordachte ontwerp trekt aan en wekt vertrouwen, en alles is volledig gratis. Het enige wat je hoeft te doen is de link naar de pagina die je wilt kopiëren invoeren, de gewenste opties kiezen en het is klaar.
LPcopier
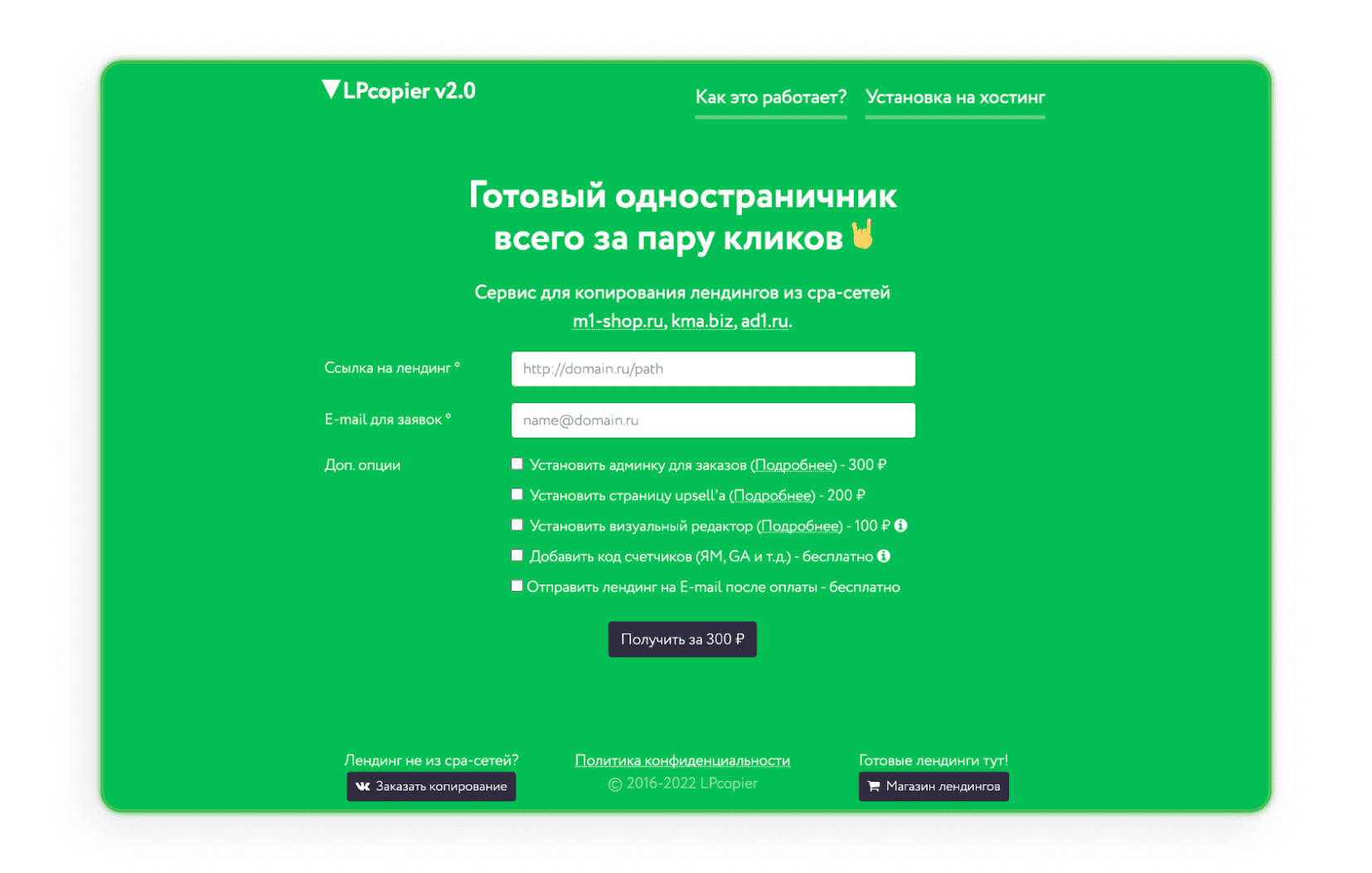
LPcopier is een Russische dienst die zich richt op affiliate marketing. Het portaal biedt scraping aan voor ongeveer $5 per pagina. Extra diensten, zoals het installeren van analytische meters, worden apart in rekening gebracht. Het is ook mogelijk om een landingspagina buiten het CPA-netwerk te bestellen of een kant-en-klare landingspagina te kopen. Als Russisch je afschrikt, gebruik dan gewoon de vertaaloptie van Google.
Xdan
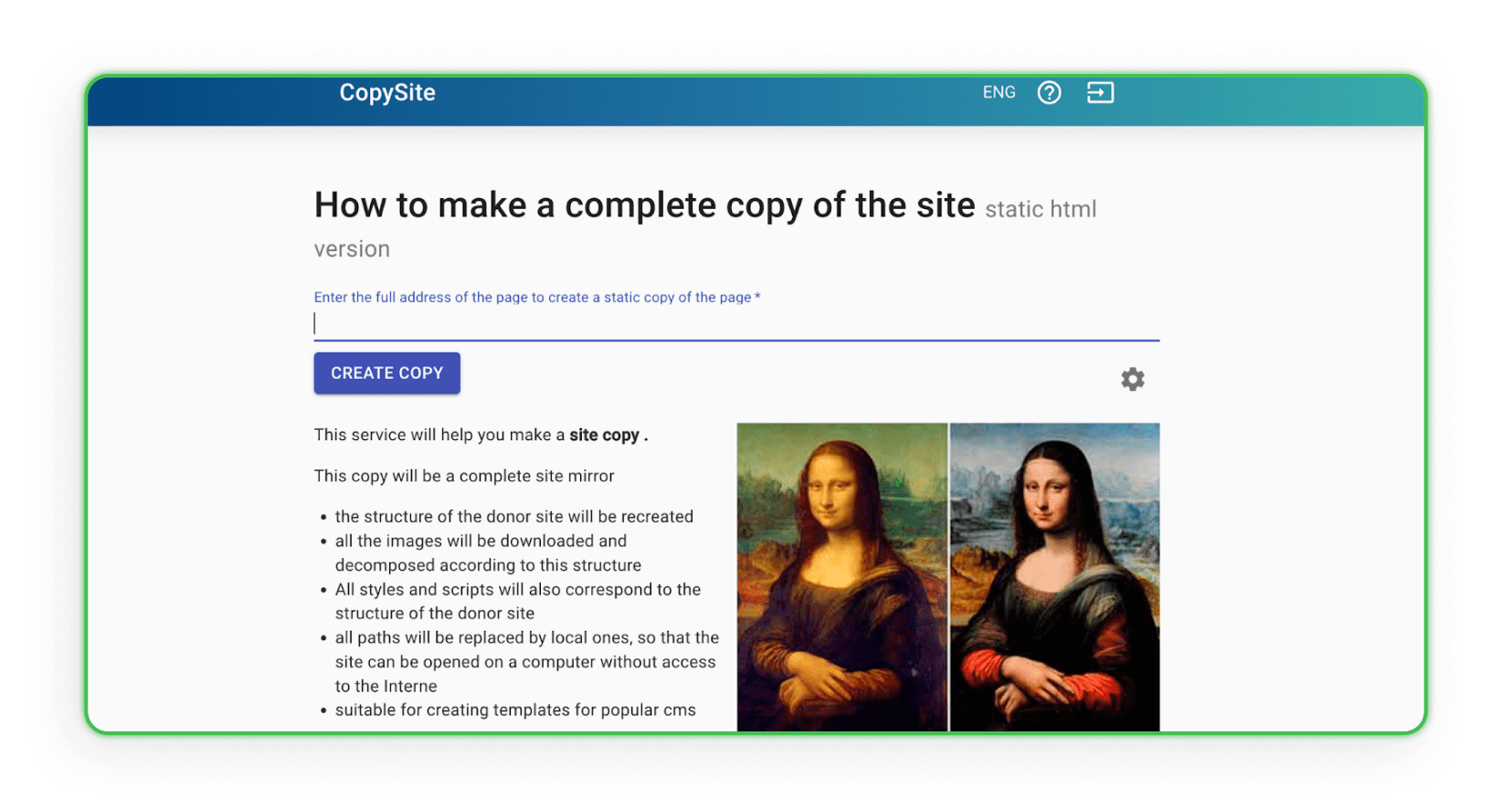
De Xdan website is ook een Russische website (beschikbaar in het Engels) die CopySite aanbiedt, oftewel web scraping-diensten. Deze website maakt het mogelijk om gratis een lokale kopie van een landingspagina te maken en biedt de mogelijkheid om HTML-counters te verwijderen of links of domeinen te vervangen.
Copysta

De Russische Copyst-dienst is een van de snelste diensten van dit type. Ze geven aan dat ze binnen 15 minuten contact met je opnemen. Het web scrapen gebeurt via een link, en je kunt de website tegen een meerprijs laten updaten.
Ik heb de website gedownload. Wat nu?
Heb je al een website gedownload? Geweldig, nu moet je nadenken over wat je ermee wilt doen. Je wilt hem zeker een beetje aanpassen. Hoe?
Hoe ontwerp ik de gekopieerde pagina opnieuw?
Om de gekopieerde pagina aan jouw behoeften aan te passen, moet je het bestand dupliceren zoals jij wilt. Om wijzigingen aan te brengen in de structuur kun je elke editor gebruiken waarmee je met code kunt werken, zoals Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS), of Sublime Text. Open een editor die voor jou handig is, pas de code aan, sla deze op en bekijk hoe de wijzigingen in de browser worden weergegeven. Bewerk het visuele uiterlijk van HTML-tags met CSS, voeg webformulieren, actieknoppen, links, enz. toe. Na het opslaan blijft het gewijzigde bestand op de computer staan met bijgewerkte functies, lay-out en gerichte acties.
Sommige websites verzamelen en analyseren alle ontwerpgegevens uit specifieke webarchieven die een systeem voor het maken en beheren van websites (CMS) hebben. Het systeem dupliceert het project met de admin en schijfruimte. Archivarix is een voorbeeld van zo'n website (het programma kan het project herstellen en archiveren).
Websites uploaden naar hosting
De laatste en belangrijkste stap in het web scrapen van landingspagina's is het uploaden ervan naar je hosting. Onthoud dat kopiëren en kleine visuele aanpassingen maken niet genoeg is. Affiliate links van anderen, scripts, vervangende pixels, JS Metrica-codes en andere tellers blijven bijna altijd in de code van de pagina staan. Deze moeten handmatig (of met betaalde programma's) worden verwijderd voordat je de pagina naar je hosting uploadt. Wil je precies weten hoe je een website uploadt naar hosting, bekijk dan ons artikel: “Hoe maak je een landingspagina? Een website stap voor stap maken”.
Hoe kun je je verdedigen tegen web scraping?
Bescherming tegen web scraping is essentieel voor het behouden van de privacy en veiligheid van je website en de gegevens daarop. Je kunt verschillende effectieve methoden toepassen om het risico op web scraping-aanvallen te minimaliseren.
• Robots.txt - Het gebruik van het robots.txt-bestand is een standaardmanier om met zoekrobots te communiceren. Je kunt aangeven welke delen van je site doorzocht mogen worden en welke niet. Hoewel eerlijke bots deze richtlijnen meestal volgen, is het goed om te weten dat dit bestand geen garantie biedt tegen alle scraping-bots.
• .htaccess - Via het .htaccess-bestand kun je de toegang blokkeren voor specifieke User Agents die bots kunnen gebruiken. Dit is een manier om te voorkomen dat ongewenste bots toegang krijgen tot je website.
• CSRF (Cross-Site Request Forgery) - Het CSRF-mechanisme kan formulieren en interacties met je site beveiligen tegen automatische scraping. Dit kan het gebruik van CSRF-tokens in formulieren inhouden.
• IP-adresfiltering - Je kunt de toegang tot je website beperken tot specifieke IP-adressen, wat kan helpen om web scraping-aanvallen te minimaliseren.
• CAPTCHA - Door CAPTCHA toe te voegen aan formulieren en interacties maak je het voor bots moeilijker om automatisch met je site te communiceren. Dit is een van de populairste verdedigingen tegen automatisch scrapen.
• Rate Limiting met mod_qos op Apache-servers - Het instellen van limieten voor het aantal verzoeken van één IP-adres binnen een bepaalde tijd kan de mogelijkheid beperken om automatisch grote hoeveelheden gegevens in korte tijd te downloaden.
• Scrapshield - De Scrapshield-dienst die door CloudFlare wordt aangeboden, is een geavanceerd hulpmiddel voor het detecteren en blokkeren van web scraping-acties, wat kan helpen bij het beschermen van je site.
Als je ooit hebt gemerkt dat je landingspagina het slachtoffer is geworden van web scraping-technieken, is er een manier om een deel van het verkeer terug naar je pagina te leiden.
Op het Afflift-forum vind je een eenvoudige JavaScript-code. Plaats deze op je pagina en je beschermt jezelf tegen het volledig verliezen van verkeer bij web scraping.
De code vind je in DEZE THREAD.
Leuk dat je hier bent!
We hopen dat je nu weet wat web scraping is, hoe je een webpagina downloadt en, het allerbelangrijkste, hoe je je aan het auteursrecht houdt. Nu is het jouw beurt om in actie te komen en te beginnen met verdienen. Heb je echter vragen over affiliate marketing of weet je niet welk programma je moet kiezen, neem dan gerust contact met ons op.
Heb je vragen? Neem gerust contact met ons op via onze kanalen.