
Blog / Affiliate marketing
Web scraping pour le marketing d'affiliation : un guide pour télécharger et personnaliser un site web selon vos besoins.

Qu'est-ce que le web scraping ?
Le web scraping consiste à télécharger des sites web sous forme de copies sur un ordinateur. Cette technologie est utilisée pour télécharger des sites entiers et extraire des données spécifiques d'intérêt à partir d'un portail donné. L'ensemble du processus est effectué à l'aide de bots, d'un robot d'indexation ou d'un script écrit en Python. Cela permet, par exemple, d'analyser les avis sur des produits ou des services sur différentes plateformes. Cela aide à identifier des tendances liées au niveau de satisfaction client et aux domaines nécessitant des améliorations. Par ailleurs, les sociétés d'analyse de marché peuvent collecter des données sur les prix des produits et services, les volumes de vente et les tendances de consommation, ce qui aide à formuler des stratégies de prix et à planifier des actions marketing.
Grâce au web scraping, les analystes peuvent également mener des études sur les comportements des utilisateurs de sites web, en analysant des aspects tels que la navigation, les interactions et le temps passé sur chaque page. Cela peut aider à optimiser l'interface utilisateur, à améliorer l'expérience utilisateur et à identifier les domaines nécessitant des ajustements supplémentaires.
En médecine et dans la recherche scientifique, le web scraping permet de collecter des données issues de publications scientifiques, d'essais cliniques ou de sites médicaux. Cela permet d'analyser les tendances de santé, d'examiner l'efficacité des thérapies ou d'identifier de nouvelles découvertes.
En résumé, le web scraping, en tant qu'outil de collecte de données pour l'analyse, ouvre la voie à une compréhension approfondie des phénomènes, des relations et des tendances dans divers domaines. Cependant, il est crucial de se rappeler des aspects éthiques et juridiques du web scraping, de faire preuve de prudence et de respecter les règles qui régissent l'accès aux données publiques et privées.
Le web scraping dans le marketing d'affiliation
Quel est le lien entre le web scraping et le marketing d'affiliation ? Commençons par l'argument le plus important qui devrait vous inciter à vous intéresser au web scraping : le temps que vous gagnez en téléchargeant les sites de vos concurrents. Tout le monde sait, ou du moins devine, que créer une bonne landing page peut prendre du temps et que le succès dépend, entre autres, de la rapidité. D'autres facteurs sont l'ouverture d'esprit, la recherche de nouvelles campagnes, la réalisation de tests et l'analyse publicitaire. Le succès revient à ceux qui ne s'arrêtent pas aux détails mais cherchent à se développer à grande échelle. Pour lancer une campagne, il faut étudier le groupe cible, le choix du GEO, les offres, etc., et préparer les supports, y compris la landing page.
Certaines personnes préfèrent utiliser les landing pages fournies par le réseau d'affiliation, d'autres utilisent des modèles prêts à l'emploi issus de constructeurs de pages, et d'autres encore choisissent de créer une page de zéro. Les deux premières options sont les plus courantes. Parfois, elles peuvent être rentables, mais ce n'est qu'une solution à court terme car la concurrence est rude et les packs de modèles disponibles s'épuisent rapidement.
Une landing page de haute qualité est la clé du succès futur et d'un bon retour sur investissement. Il convient d'ajouter que toutes les landing pages des concurrents ne donneront pas le résultat escompté. Il vaut mieux affiner la page souhaitée en tenant compte des critères de la future campagne publicitaire.
Bien sûr, il faut toujours veiller à agir légalement, c'est-à-dire selon certaines règles que vous allez découvrir dans un instant.
Le web scraping est-il légal ?
Oui. Le web scraping n'est pas interdit ; les entreprises avec lesquelles vous signez le font légalement. Malheureusement, il y aura toujours quelqu'un pour utiliser Startsool à des fins de piraterie. Le web scraping peut être utilisé pour pratiquer des prix déloyaux et voler du contenu protégé par droits d'auteur. Un propriétaire de site web victime de scraping peut subir des pertes financières importantes. Fait intéressant, le web scraping a été utilisé par plusieurs entreprises étrangères pour sauvegarder des stories Instagram et Facebook censées être limitées dans le temps.
Le scraping est autorisé si vous respectez le droit d'auteur et les normes établies. Toutefois, si vous décidez de passer du côté obscur, ce qui n'est pas accepté sur MyLead, vous pouvez faire face à diverses conséquences.
Quelques bonnes pratiques lors du scraping de sites web
Pensez au RGPD
En ce qui concerne les pays de l'UE, vous devez respecter le règlement européen sur la protection des données, communément appelé RGPD. Si vous ne scrappez pas de données personnelles, vous n'avez pas trop à vous en soucier. Rappelons que les données personnelles sont toutes les données permettant d'identifier une personne, par exemple :
• prénom et nom,
• e-mail,
• numéro de téléphone,
• adresse,
• nom d'utilisateur (ex. login/pseudo),
• adresse IP,
• informations sur le numéro de carte bancaire ou de crédit,
• données médicales ou biométriques.
Pour faire du web scraping, vous devez avoir une raison de stocker des données personnelles. Exemples de telles raisons :
1. Intérêt légitime
Il faut prouver que le traitement des données est nécessaire pour l'activité commerciale légitime. Cependant, cela ne s'applique pas si ces intérêts sont supplantés par les intérêts ou les droits et libertés fondamentaux de la personne dont vous souhaitez traiter les données.
2. Consentement du client
Chaque personne dont vous souhaitez collecter les données doit donner son consentement à la collecte, au stockage et à l'utilisation de ses données comme vous l'entendez, par exemple à des fins marketing.
Si vous n'avez ni intérêt légitime ni consentement du client, vous violez le RGPD, ce qui peut entraîner une amende, une restriction de liberté, ou une peine de prison allant jusqu'à deux ans.
Attention !
Le RGPD ne s'applique qu'aux résidents des pays de l'Union européenne ; il ne concerne donc pas des pays comme les États-Unis, le Japon ou l'Afghanistan.
Respectez le droit d'auteur
Le droit d'auteur est le droit exclusif à toute œuvre réalisée, par exemple un article, une photo, une vidéo, une musique, etc. Vous pouvez deviner que le droit d'auteur est très important dans le web scraping, car de nombreuses données sur Internet sont protégées. Bien sûr, il existe des exceptions où vous pouvez scraper et utiliser des données sans enfreindre la loi, et ce sont :
• utilisation pour un usage personnel ou public,
• utilisation à des fins didactiques ou scientifiques,
• utilisation dans le cadre du droit de citation.
Web scraping - par où commencer ?
1. URL
La première étape consiste à trouver l'URL de la page qui vous intéresse. Ensuite, précisez le sujet que vous souhaitez choisir. Votre imagination et vos sources de données sont vos seules limites.
2. Code HTML
Apprenez la structure du code HTML. Il est nécessaire de connaître le HTML pour trouver un élément à télécharger sur les sites de vos concurrents. Le mieux est d'aller sur l'élément dans le navigateur et d'utiliser l'option Inspecter. Vous verrez alors les balises HTML et pourrez identifier le composant d'intérêt. Voici un exemple sur Wikipédia :
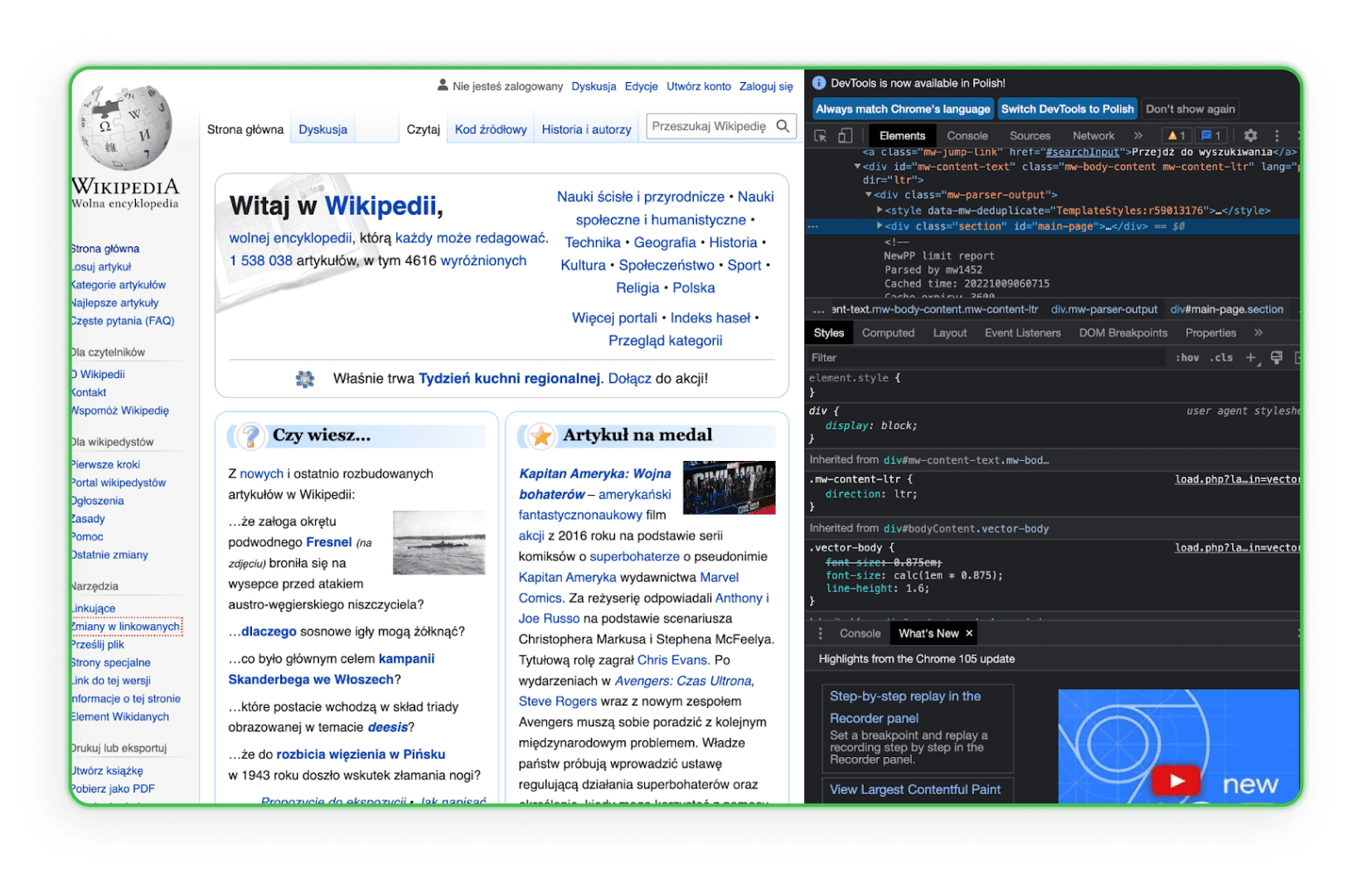
Comme vous pouvez le voir, lorsque vous survolez une ligne de code, l'élément correspondant sur la page est mis en surbrillance.
3. Environnement de travail
Votre environnement de travail doit être prêt. Vous verrez plus tard que vous aurez besoin d'éditeurs de texte comme Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS), ou Sublime Text, alors procurez-vous en un dès maintenant.
Bibliothèques pour le web scraping - comment sauvegarder une page web ?
Les bibliothèques de web scraping sont des collections organisées de scripts et de fonctions écrites dans des langages de programmation spécifiques qui aident à récupérer automatiquement des données à partir de sites web. Elles permettent aux développeurs d'analyser rapidement, de filtrer et d'extraire le contenu du code HTML ou XML des pages web. Grâce à elles, au lieu d'écrire chaque fonction à la main, les développeurs peuvent utiliser des solutions prêtes à l'emploi et optimisées pour rechercher, naviguer et manipuler la structure des sites.
Simple HTML DOM Parser - Une bibliothèque PHP
Cet outil est destiné aux développeurs PHP et facilite la manipulation et l'interaction avec le code HTML. Il permet de rechercher, modifier ou extraire facilement et intuitivement des sections spécifiques du code HTML.
Beautiful Soup - Une bibliothèque Python
Beautiful Soup est une bibliothèque Python conçue pour analyser les documents HTML et XML. Elle a été créée pour naviguer, rechercher et modifier facilement l'arbre DOM tout en offrant des interfaces intuitives pour extraire des données des pages web.
Scrapy - Une bibliothèque Python
Scrapy est une puissante bibliothèque et un framework pour le web scraping en Python. Elle permet de créer des bots spécialisés capables de scanner des pages, de suivre des liens, d'extraire les informations nécessaires et de les enregistrer dans les formats souhaités. Scrapy est parfait pour les applications plus complexes nécessitant une recherche approfondie ou une interaction avec des formulaires et autres éléments de page.
Sauvegarder la page via le navigateur
N'importe qui, y compris vous, peut sauvegarder une page sélectionnée sur son ordinateur en utilisant n'importe quel navigateur. Ce processus prend quelques minutes et produit une copie de la page sous forme de fichier HTML et de dossier sur l'ordinateur de l'utilisateur. La copie s'ouvre dans le navigateur et semble assez fluide. Cependant, pour sauvegarder une très grande page, ce processus devra être répété plusieurs fois.
De nombreuses entreprises et freelances sur Internet feront tout cela pour vous moyennant des frais. Un des services de copie de site web est ProWebScraper. Une version d'essai est disponible, vous permettant de télécharger 100 pages. Ensuite, bien sûr, il faudra payer. Les offres commencent à 40 $ par mois, selon le nombre de pages à scraper. Vous pouvez toujours trouver un autre site avec une période d'essai gratuite. Il est à noter que certains portails permettent de vérifier si une page est copiable, car de nombreux sites se protègent contre cela.
Des outils plus conviviaux pour les débutants
Tout le monde ne souhaitant pas se lancer dans le web scraping n'est pas un développeur expérimenté. Pour ceux qui recherchent des solutions moins techniques et plus intuitives, il existe des outils conçus pour la facilité d'utilisation. Grâce à des interfaces visuelles et des mécanismes simples, les logiciels suivants permettent de collecter efficacement des données sans avoir besoin de coder.
ZennoPoster
ZennoPoster est un outil d'automatisation et de web scraping qui s'adresse davantage à ceux qui ne sont pas nécessairement experts en programmation. Son interface visuelle conviviale permet de créer des scripts de scraping et d'autres tâches automatisées sur navigateur.
Prix : L'outil coûte 37 $ par mois, mais dispose d'une période d'essai de 14 jours.
Browser Automation Studio
BAS est un autre programme convivial d'automatisation de navigateur et de web scraping. Il dispose d'outils intégrés de création de scripts permettant l'extraction de données, la navigation sur des pages web et bien d'autres fonctions sans aucune connaissance en programmation.
Prix : L'outil est gratuit.
Octoparse
Octoparse est une application de web scraping qui collecte facilement de grandes quantités de données sur les sites web. Son interface visuelle permet aux utilisateurs de spécifier les données à collecter, et Octoparse s'occupe du reste.
Prix : Une version gratuite de cet outil existe, avec certaines restrictions. Dans la version gratuite, les utilisateurs peuvent stocker dix tâches sur leur compte. Toutes les tâches ne peuvent être exécutées que sur des appareils locaux en utilisant l'IP de l'utilisateur. L'exportation de données dans le plan gratuit est limitée à 10 000 lignes par export, même si l'outil permet un nombre illimité de scans de pages en une seule fois. Il peut également être utilisé sur un nombre illimité d'appareils. Cependant, le support technique est limité dans cette version. Les versions payantes commencent à 75 $ par mois.
import.io
import.io est un outil de web scraping basé sur le cloud qui facilite la création et l'exécution de scripts pour extraire des données des sites web. Il propose également des fonctionnalités qui structurent automatiquement les données collectées et les convertissent en formats utiles comme Excel ou JSON.
Prix : L'outil propose une démo gratuite, mais les forfaits payants commencent à 399 $ par mois.
Services de web scraping en ligne
Le web scraping en ligne fonctionne comme des parseurs (analyseurs de composants), mais leur principal avantage est la possibilité de travailler en ligne sans avoir à télécharger et installer le programme sur votre ordinateur. Le principe de fonctionnement des sites proposant du web scraping en ligne est assez simple. On saisit l'URL de la page qui nous intéresse, on règle les paramètres nécessaires (on peut copier la version mobile, renommer tous les fichiers, le programme sauvegarde HTML, CSS, JavaScript, polices) et on télécharge l'archive. Grâce à ce service, le webmaster peut sauvegarder n'importe quelle landing page, puis l'adapter à son format et effectuer les corrections nécessaires.
Save a Web 2 ZIP

Save a Web 2 ZIP est le site le plus populaire pour le web scraping via service navigateur. Son design simple et réfléchi attire et inspire confiance, et tout est entièrement gratuit. Il suffit de fournir le lien de la page à copier, de choisir les options souhaitées et c'est prêt.
LPcopier
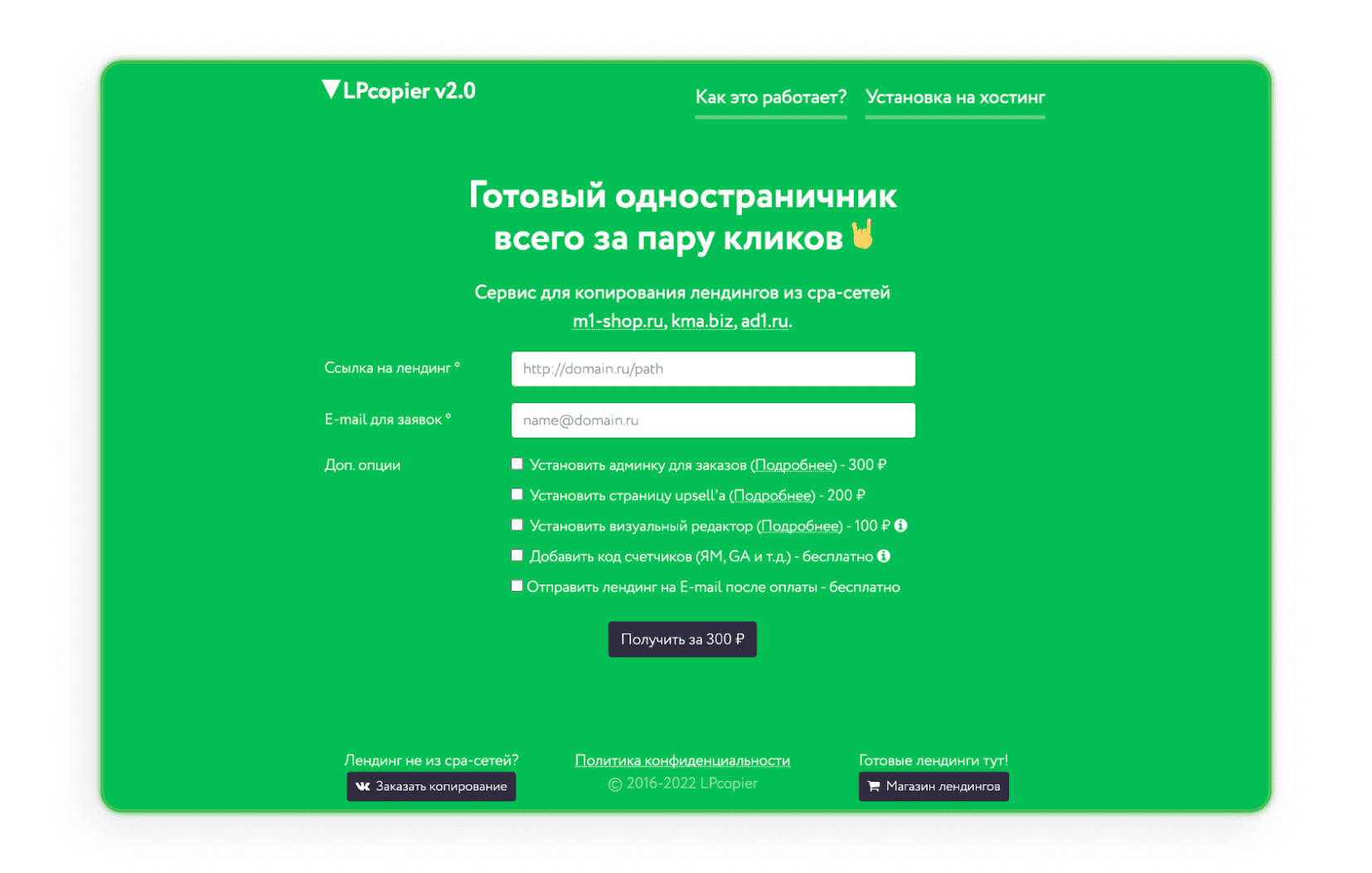
LPcopier est un service russe destiné au marketing d'affiliation. Le portail permet le scraping pour environ 5 $ par page. Les services supplémentaires, comme l'installation de compteurs analytiques, sont facturés séparément. Il est aussi possible de commander une landing page hors réseau CPA ou une page déjà prête. Si le russe vous effraie, utilisez simplement l'option de traduction proposée par Google.
Xdan
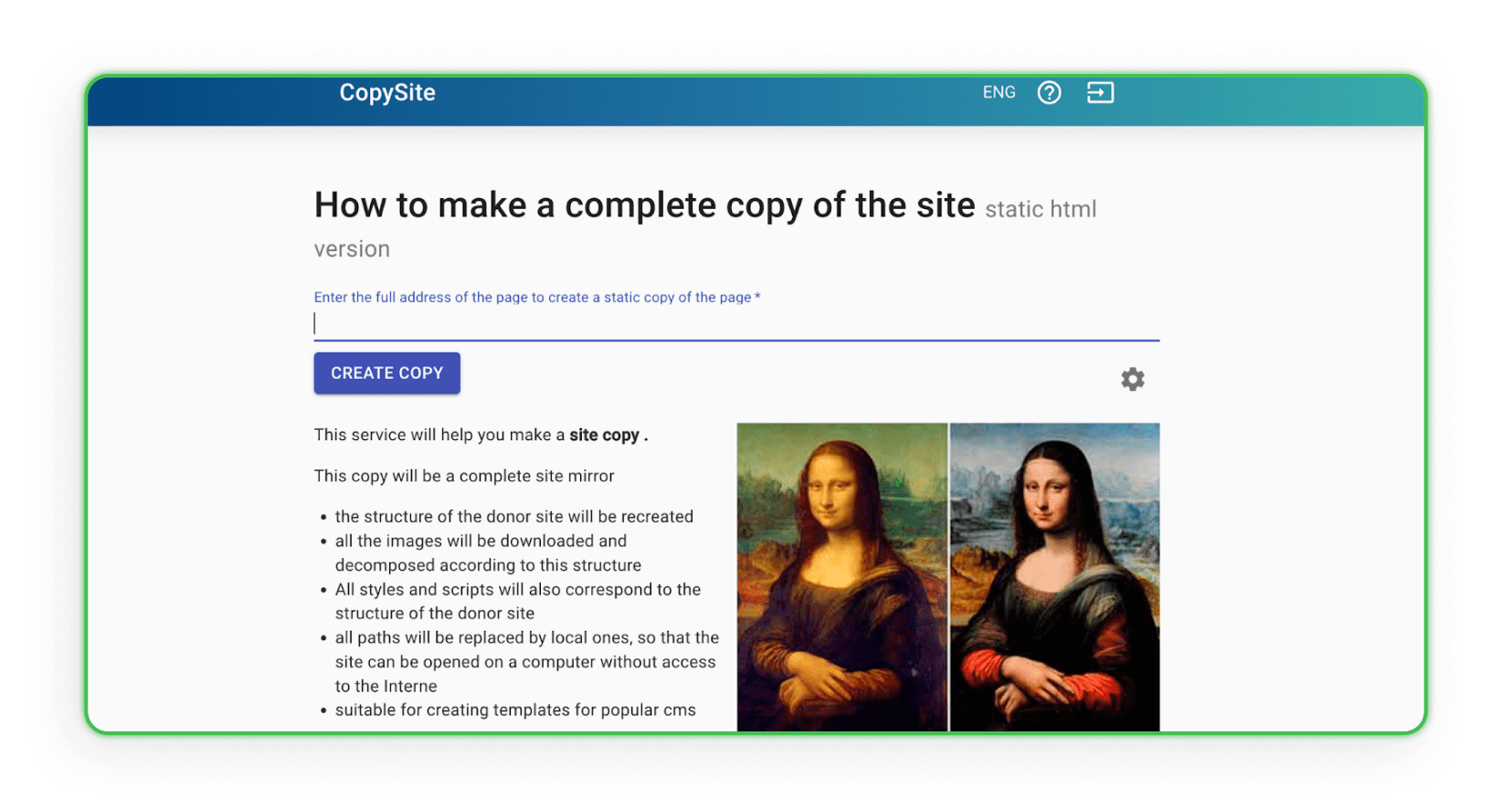
Le site Xdan est également un site russe (disponible en anglais) proposant CopySite, c'est-à-dire des services de web scraping. Ce site vous permet de créer gratuitement une copie locale d'une landing page et de choisir de nettoyer les compteurs HTML ou de remplacer les liens ou domaines.
Copysta

Le service russe Copysta est l'un des services de ce type les plus rapides du marché. Ils déclarent vous contacter sous 15 minutes. Le web scraping se fait via un lien, et vous pouvez mettre à jour le site moyennant un supplément.
J'ai téléchargé le site web. Et maintenant ?
Avez-vous déjà téléchargé un site web ? Parfait, il faut maintenant réfléchir à ce que vous souhaitez en faire. Vous voudrez certainement le modifier un peu. Comment ?
Comment refaire la page copiée ?
Pour refaire la page copiée selon vos besoins, il suffit de dupliquer la ressource comme bon vous semble. Pour modifier la structure, vous pouvez utiliser n'importe quel éditeur permettant de travailler sur le code, comme Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS), ou Sublime Text. Ouvrez l'éditeur qui vous convient, personnalisez le code, puis enregistrez et voyez comment les modifications s'affichent dans le navigateur. Modifiez l'apparence visuelle des balises HTML via CSS, ajoutez des formulaires web, des boutons d'action, des liens, etc. Après enregistrement, le fichier modifié restera sur l'ordinateur avec les fonctions, la mise en page et les actions ciblées mises à jour.
Certains sites collectent et analysent toutes les données de conception à partir d'archives web spécifiques disposant d'un système de création et de gestion de site (CMS). Le système duplique le projet avec l'admin et l'espace disque. Archivarix est un exemple de tel site (le programme peut restaurer et archiver le projet).
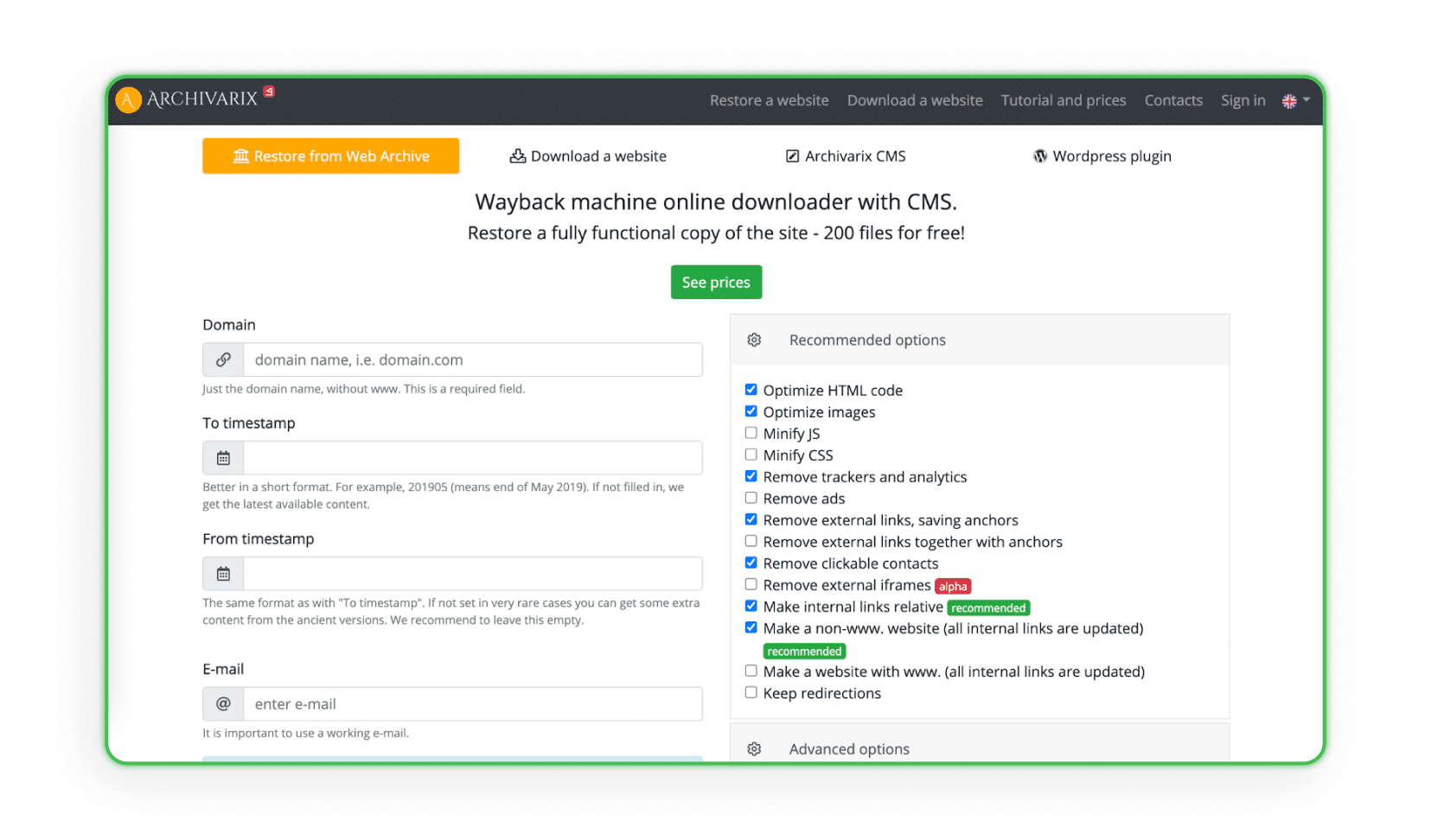
Téléversement des sites sur un hébergement
La dernière étape, et la plus importante, du web scraping des landing pages est de les téléverser sur votre hébergement. Rappelez-vous que copier et faire de petits changements visuels ne suffit pas. Les liens d'affiliation, scripts, pixels de remplacement, codes JS Metrica et autres compteurs d'autrui restent presque toujours dans le code de la page. Ils doivent être supprimés manuellement (ou avec des programmes payants) avant le téléversement. Si vous voulez savoir exactement comment téléverser votre site sur un hébergement, consultez notre article : « Comment créer une landing page ? Création d'un site étape par étape ».
Comment se défendre contre le web scraping ?
La protection contre le web scraping est essentielle pour préserver la confidentialité et la sécurité de votre site et de ses données. Plusieurs méthodes efficaces peuvent être appliquées pour minimiser le risque d'attaques de web scraping.
• Robots.txt - Utiliser le fichier robots.txt est une méthode standard pour communiquer avec les robots d'indexation. Vous pouvez spécifier quelles parties de votre site doivent être explorées ou non. Bien que les bots honnêtes respectent généralement ces consignes, il est important de noter que ce fichier ne garantit pas une protection contre tous les bots de scraping.
• .htaccess - Grâce au fichier .htaccess, vous pouvez bloquer l'accès à certains User Agents utilisés par les bots. C'est un moyen d'empêcher l'accès de bots indésirables à votre site./li>
• CSRF (Cross-Site Request Forgery) - Le mécanisme CSRF peut sécuriser les formulaires et les interactions avec votre site contre le scraping automatique. Cela peut impliquer l'utilisation de jetons CSRF dans les formulaires./li>
• Filtrage des adresses IP - Vous pouvez limiter l'accès à votre site à certaines adresses IP, ce qui peut aider à réduire les attaques de web scraping.
• CAPTCHA - Ajouter un CAPTCHA aux formulaires et interactions peut compliquer la tâche des bots automatisés. C'est l'une des défenses les plus populaires contre le scraping automatique./li>
• Limitation du débit avec mod_qos sur les serveurs Apache - Définir des limites sur le nombre de requêtes d'une même adresse IP dans un temps donné peut limiter la possibilité de téléchargement automatique de grandes quantités de données en peu de temps./li>
• Scrapshield - Le service Scrapshield proposé par CloudFlare est un outil avancé pour détecter et bloquer les actions de web scraping, ce qui peut aider à protéger votre site./li>
Si vous avez déjà constaté que votre landing page a été victime de techniques de web scraping, il existe un moyen de rediriger une partie du trafic vers votre page.
Sur le forum Afflift, vous trouverez un code JavaScript simple. Placez-le sur votre page, et il vous protégera contre la perte totale de trafic en cas de web scraping.
Le code se trouve dans CETTE DISCUSSION.
Heureux de vous voir ici !
Nous espérons que vous savez désormais ce qu'est le web scraping, comment télécharger une page web et, surtout, comment respecter le droit d'auteur. C'est maintenant à vous de jouer et de commencer à gagner de l'argent. Cependant, si vous avez des questions sur le marketing d'affiliation ou si vous ne savez pas quel programme choisir, veuillez nous contacter.
Vous avez des questions ? N'hésitez pas à nous contacter via nos canaux.