
Blog / Affiliate marketing
Web scraping per il marketing di affiliazione: una guida su come scaricare e personalizzare un sito web in base alle tue esigenze.

Cos'è il web scraping?
Il web scraping consiste nello scaricare siti web come copie su un computer. Questa tecnologia viene utilizzata per scaricare interi siti web ed estrarre dati specifici di interesse da un dato portale. L'intero processo viene eseguito utilizzando bot, un robot di indicizzazione o uno script scritto in Python. Durante le recensioni di prodotti o servizi su varie piattaforme, questo aiuta a identificare modelli relativi ai livelli di soddisfazione dei clienti e alle aree che necessitano di miglioramenti. Nel frattempo, le società di analisi di mercato possono raccogliere dati su prezzi di prodotti e servizi, volumi di vendita e tendenze dei consumatori, aiutando nella formulazione di strategie di prezzo e nella pianificazione delle azioni di marketing.
Grazie al web scraping, gli analisti possono anche condurre studi sui comportamenti degli utenti dei siti web, analizzando aspetti come la navigazione, le interazioni e il tempo trascorso sulle singole pagine. Questo può aiutare a ottimizzare l'interfaccia utente, migliorare l'esperienza dell'utente e individuare le aree che richiedono ulteriori perfezionamenti.
In medicina e nella ricerca scientifica, il web scraping può raccogliere dati da pubblicazioni scientifiche, studi clinici o siti web medici. Questo consente l'analisi delle tendenze sanitarie, l'esame dell'efficacia delle terapie o l'identificazione di nuove scoperte.
In sintesi, il web scraping come strumento di raccolta dati per l'analisi apre le porte a una comprensione più profonda di fenomeni, relazioni e tendenze in vari settori. Tuttavia, è fondamentale ricordare gli aspetti etici e legali del web scraping, agire con cautela e rispettare le regole che disciplinano l'accesso ai dati pubblici e privati.
Web scraping nel marketing di affiliazione
Come si collega il web scraping al marketing di affiliazione? Iniziamo con l'argomento più significativo che ti spinge a interessarti al web scraping, ovvero il tempo risparmiato che ottieni scaricando i siti web dei concorrenti. Tutti sanno, o almeno immaginano, che creare una buona landing page può richiedere tempo e che il successo dipende, tra le altre cose, dal tempismo. Altri fattori sono l'apertura a un cambio di approccio, la ricerca di nuove campagne, l'esecuzione di test e l'analisi della pubblicità. Il successo è raggiunto da chi non si ferma ai dettagli ma cerca modi per scalare. Per eseguire una campagna, è necessario ricercare il gruppo target, la selezione GEO, le offerte, ecc., e preparare i materiali, inclusa una landing page.
Alcune persone preferiscono le landing page fornite dal network di affiliazione, altri usano template già pronti dei page builder, altri ancora scelgono di creare una landing page da zero. Le prime due opzioni sono le più comuni. A volte possono risultare redditizie, ma si tratta di una soluzione a breve termine poiché la concorrenza è feroce e i pacchetti di template disponibili si esauriscono rapidamente.
Una landing page di alta qualità è la chiave del successo futuro e di un buon ritorno sull'investimento. Vale la pena aggiungere che non tutte le landing page dei concorrenti possono portare il risultato atteso. È meglio perfezionare la landing page desiderata, tenendo conto dei criteri della futura campagna pubblicitaria.
Ovviamente, devi ricordare di fare tutto legalmente, cioè secondo determinate regole, che scoprirai tra poco.
Il web scraping è legale?
Sì. Il web scraping non è vietato; le aziende che firmi lo fanno legalmente. Purtroppo, ci sarà sempre qualcuno che inizierà a utilizzare Startsool per attività di pirateria. Il web scraping può essere utilizzato per perseguire pratiche di prezzo sleali e rubare contenuti protetti da copyright. Un proprietario di sito web che subisce scraping può subire perdite finanziarie sostanziali. Curiosamente, il web scraping è stato utilizzato da diverse aziende straniere per salvare storie di Instagram e Facebook che dovrebbero essere a tempo limitato.
Lo scraping è accettabile se rispetti il copyright e aderisci agli standard stabiliti. Tuttavia, se decidi di passare al lato oscuro non accettato su MyLead, potresti affrontare varie conseguenze.
Alcune buone pratiche durante lo scraping dei siti web
Ricorda il GDPR
Per quanto riguarda i paesi dell'UE, devi rispettare il regolamento sulla protezione dei dati dell'UE, comunemente noto come GDPR. Se non stai raschiando dati personali, non devi preoccuparti troppo. Ricordiamo che i dati personali sono qualsiasi dato che può identificare una persona, ad esempio:
• nome e cognome,
• email,
• numero di telefono,
• indirizzo,
• nome utente (ad es. login/nickname),
• indirizzo IP,
• informazioni sul numero di carta di credito o debito,
• dati medici o biometrici.
Per fare web scraping, hai bisogno di una motivazione per conservare i dati personali. Esempi di tali motivazioni includono:
1. Interesse legittimo
Deve essere dimostrato che il trattamento dei dati è necessario per l'attività aziendale legittima. Tuttavia, ciò non si applica alle situazioni in cui questi interessi sono superati dagli interessi o dai diritti e libertà fondamentali della persona di cui desideri trattare i dati.
2. Consenso del cliente
Ogni persona di cui desideri raccogliere i dati deve acconsentire alla raccolta, conservazione e utilizzo dei propri dati come intendi, ad esempio per scopi di marketing.
Se non hai un interesse legittimo o il consenso del cliente, stai violando il GDPR, il che può comportare una multa, una restrizione della libertà o la reclusione fino a due anni.
Attenzione!
Il GDPR si applica solo ai residenti nei paesi dell'Unione Europea, quindi non si applica a paesi come Stati Uniti, Giappone o Afghanistan.
Rispetta il copyright
Il copyright è il diritto esclusivo su qualsiasi opera realizzata, ad esempio un articolo, una foto, un video, un brano musicale, ecc. Puoi immaginare che il copyright sia molto importante nel web scraping, perché molti dati su Internet sono protetti da copyright. Ovviamente, ci sono eccezioni in cui puoi fare scraping e utilizzare i dati senza violare le leggi sul copyright, e sono:
• utilizzo per uso pubblico personale,
• utilizzo per scopi didattici o attività scientifica,
• utilizzo secondo il diritto di citazione.
Web scraping - da dove iniziare?
1. URL
Il primo passo è trovare l'URL della pagina che ti interessa. Poi, specifica l'argomento che vuoi scegliere. La tua immaginazione e le fonti di dati sono i tuoi unici limiti.
2. Codice HTML
Impara la struttura del codice HTML. Devi conoscere l'HTML per trovare un elemento che scarichi dai siti web dei tuoi concorrenti. Il modo migliore è andare sull'elemento nel browser e usare l'opzione Ispeziona. Vedrai quindi i tag HTML e potrai identificare il componente di interesse. Ecco un esempio su Wikipedia:
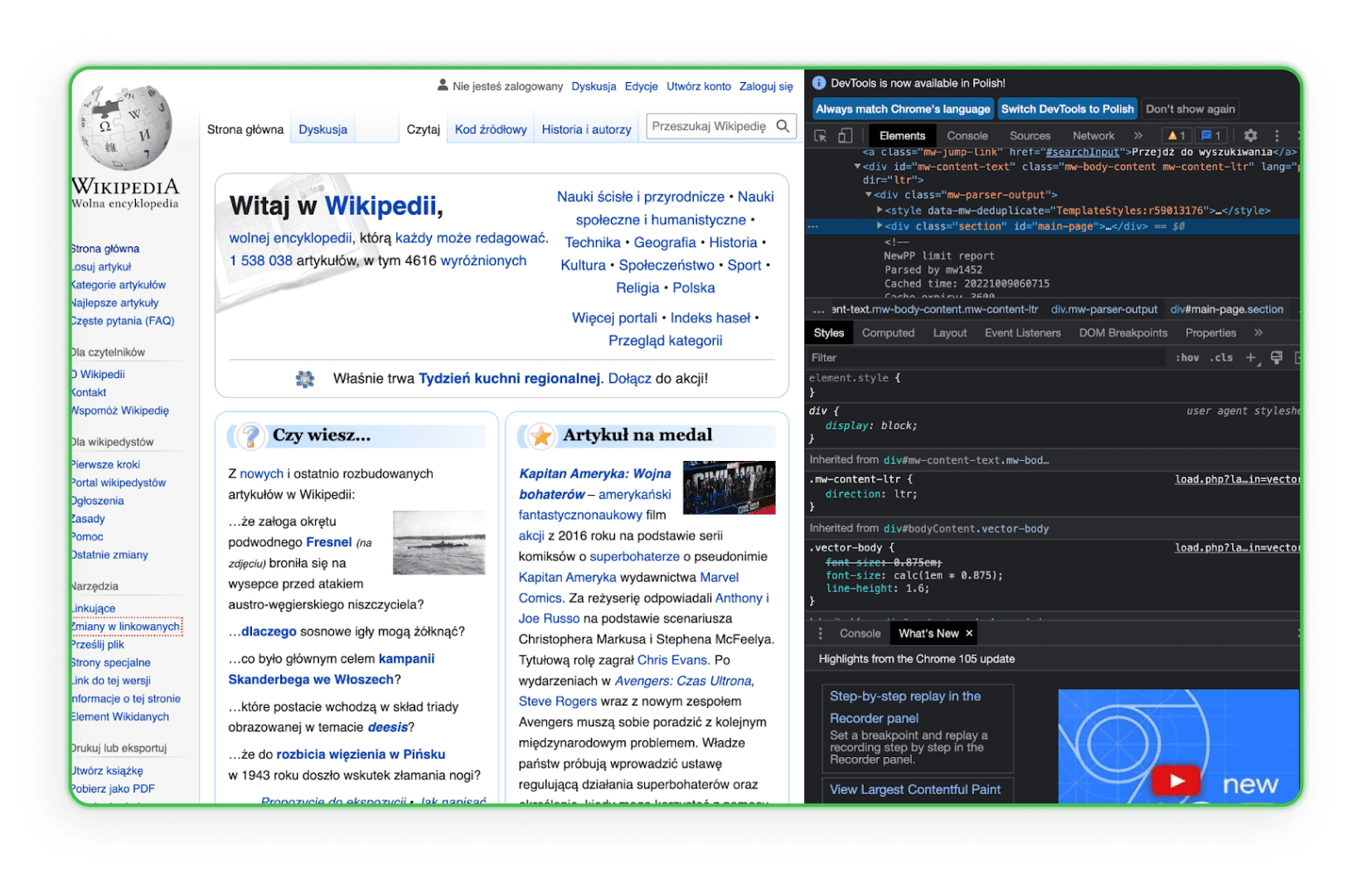
Come puoi vedere, quando passi il mouse su una determinata riga di codice, l'elemento corrispondente a questa riga di codice viene evidenziato sulla pagina.
3. Ambiente di lavoro
Il tuo ambiente di lavoro dovrebbe essere pronto. Scoprirai più avanti che avrai bisogno di editor di testo come Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS), o Sublime Text, quindi procuratene uno ora.
Librerie per il web scraping - come salvare una pagina web?
Le librerie di web scraping sono raccolte organizzate di script e funzioni scritte in linguaggi di programmazione specifici che aiutano a recuperare automaticamente dati dai siti web. Consentono agli sviluppatori di analizzare, filtrare ed estrarre rapidamente contenuti dal codice HTML o XML delle pagine web. Con esse, invece di scrivere ogni funzione manualmente, gli sviluppatori possono utilizzare soluzioni pronte e ottimizzate per cercare, navigare e manipolare la struttura dei siti web.
Simple HTML DOM Parser - Una libreria PHP
Questo strumento è per sviluppatori PHP e facilita la manipolazione e l'interazione con il codice HTML. Consente di cercare, modificare o estrarre facilmente e intuitivamente sezioni specifiche del codice HTML.
Beautiful Soup - Una libreria Python
Beautiful Soup è una libreria Python progettata per analizzare documenti HTML e XML. È stata creata per navigare facilmente, cercare e modificare l'albero DOM offrendo interfacce intuitive per estrarre dati dalle pagine web.
Scrapy - Una libreria Python
Scrapy è una potente libreria e framework per il web scraping in Python. Permette la creazione di bot specializzati che possono scansionare le pagine, seguire i link, estrarre le informazioni necessarie e salvarle nei formati desiderati. Scrapy è perfetta per applicazioni più complesse che richiedono una ricerca approfondita delle pagine web o l'interazione con moduli e altri elementi della pagina.
Salvare la pagina tramite browser
Chiunque, incluso te, può salvare la pagina selezionata sul proprio computer accedendo a qualsiasi browser. Questo processo richiede solo pochi minuti e produce una copia duplicata della pagina come file HTML e cartella sul computer dell'utente. L'intera copia della pagina si apre nel browser e appare abbastanza fedele. Tuttavia, per salvare una pagina davvero grande, questo processo dovrà essere ripetuto molte volte.
Molte aziende e freelance su Internet faranno tutto per te a pagamento. Uno dei servizi di copia siti web è ProWebScraper. È disponibile una versione di prova, con cui puoi scaricare 100 pagine. Successivamente, ovviamente, dovrai pagare. I piani partono da 40$ al mese, a seconda di quante pagine vuoi raschiare. Puoi sempre trovare un altro sito con un periodo di prova gratuito. Vale la pena menzionare che alcuni portali ti permettono di verificare se una determinata pagina è copiabile perché molti siti si proteggono da questo.
Strumenti più user-friendly per principianti
Non tutti coloro che vogliono approfondire il web scraping sono sviluppatori esperti. Per chi cerca soluzioni meno tecniche e più intuitive, esistono strumenti progettati specificamente per la facilità d'uso. Con interfacce visive e meccanismi semplici, il software seguente consente una raccolta efficiente dei dati dai siti web senza la necessità di programmare.
ZennoPoster
ZennoPoster è uno strumento di automazione e web scraping che si rivolge soprattutto a chi non è necessariamente esperto di programmazione. La sua interfaccia visiva user-friendly consente la creazione di script di scraping e altre attività automatizzate del browser.
Prezzo: Lo strumento costa 37$ al mese, ma ha un periodo di prova di 14 giorni.
Browser Automation Studio
BAS è un altro programma di automazione del browser e web scraping user-friendly. Dispone di strumenti integrati per la creazione di script che consentono l'estrazione di dati, la navigazione nelle pagine web e molte altre funzioni senza alcuna conoscenza di programmazione.
Prezzo: Lo strumento è gratuito.
Octoparse
Octoparse è un'applicazione di web scraping che raccoglie facilmente grandi quantità di dati dai siti web. La sua interfaccia visiva consente agli utenti di specificare quali dati desiderano raccogliere, e Octoparse si occupa del resto.
Prezzo: Una versione di questo strumento è gratuita, ma presenta alcune restrizioni. Nella versione gratuita, gli utenti possono memorizzare dieci attività nei loro account. Tutte le attività possono essere eseguite solo su dispositivi locali utilizzando l'IP dell'utente. L'esportazione dei dati nel piano gratuito è limitata a 10.000 righe per esportazione, anche se lo strumento consente scansioni illimitate di pagine web in una sola volta. Può anche essere utilizzato su un numero qualsiasi di dispositivi. Tuttavia, il supporto tecnico in questa versione è limitato. Le versioni a pagamento partono da 75$ al mese.
import.io
import.io è uno strumento di web scraping basato su cloud che facilita la creazione e l'esecuzione di script per estrarre dati dai siti web. Offre anche funzionalità che strutturano automaticamente i dati raccolti e li convertono in formati utili come Excel o JSON.
Prezzo: Lo strumento offre una demo gratuita, ma i prezzi dei pacchetti a pagamento partono da 399$ al mese.
Servizi di web scraping online
Il web scraping online funziona come parser (analizzatori di componenti), ma il loro principale vantaggio è la possibilità di lavorare online senza scaricare e installare il programma sul proprio computer. Il principio di funzionamento dei siti che offrono il web scraping online è abbastanza semplice. Inseriamo l'URL della pagina che ci interessa, impostiamo le impostazioni necessarie (puoi copiare la versione mobile della pagina e rinominare tutti i file, il programma salva HTML, CSS, JavaScript, font) e scarichiamo l'archivio. Con questo servizio, il webmaster può salvare qualsiasi landing page e poi inserire il proprio formato e le correzioni necessarie.
Save a Web 2 ZIP

Save a Web 2 ZIP è il sito più popolare per il web scraping tramite servizio browser. Il suo design semplice e curato attira e ispira fiducia, e tutto è completamente gratuito. Basta fornire il link alla pagina che vuoi copiare, scegliere le opzioni desiderate, ed è fatto.
LPcopier
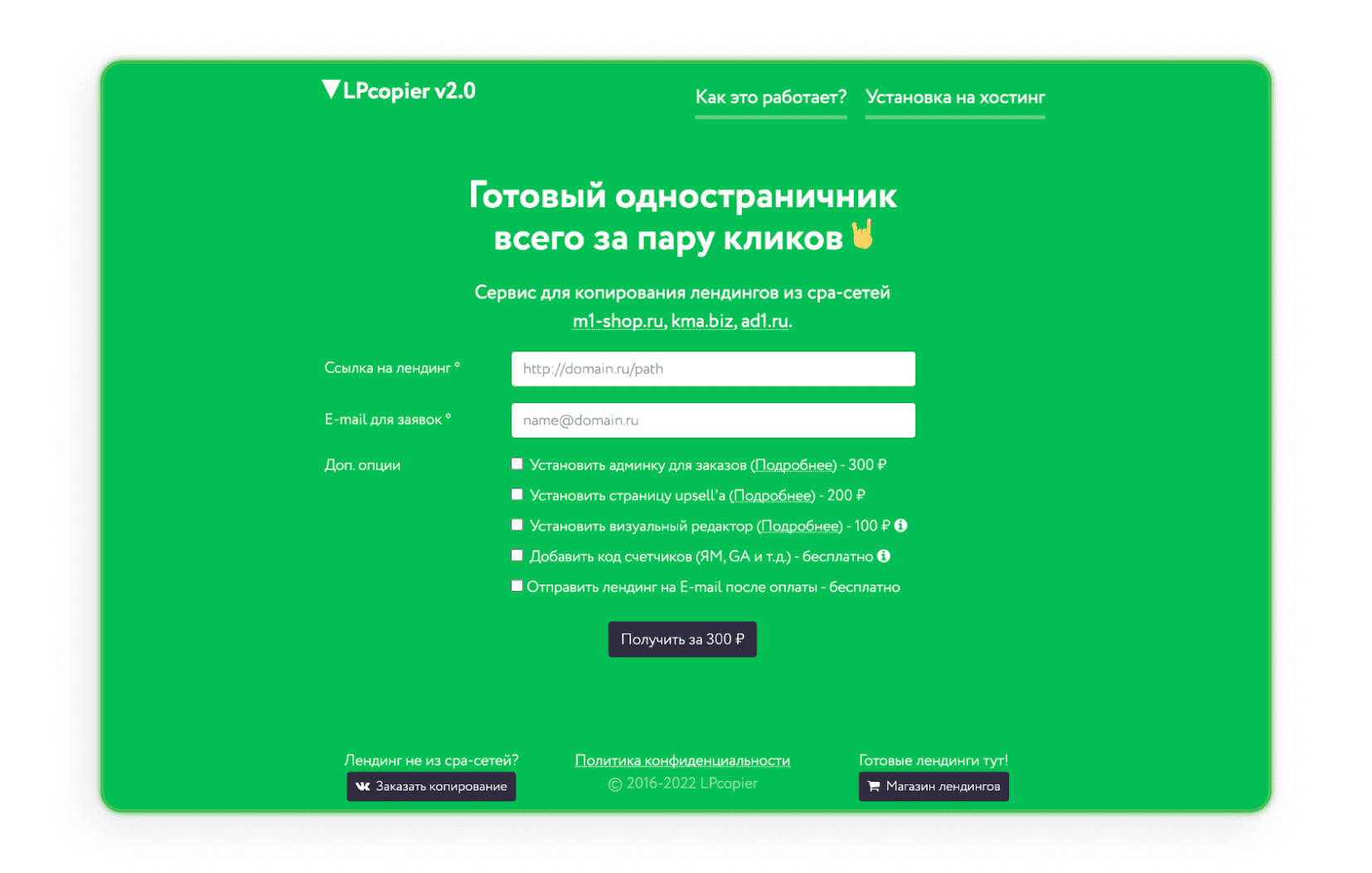
LPcopier è un servizio russo che si rivolge al marketing di affiliazione. Il portale consente lo scraping per circa 5$ a pagina. Servizi aggiuntivi, come l'installazione di contatori analitici, sono considerati separatamente in termini di costo. È anche possibile ordinare una landing page al di fuori della rete CPA o una landing già pronta. Se il russo ti spaventa, usa semplicemente l'opzione di traduzione offerta da Google.
Xdan
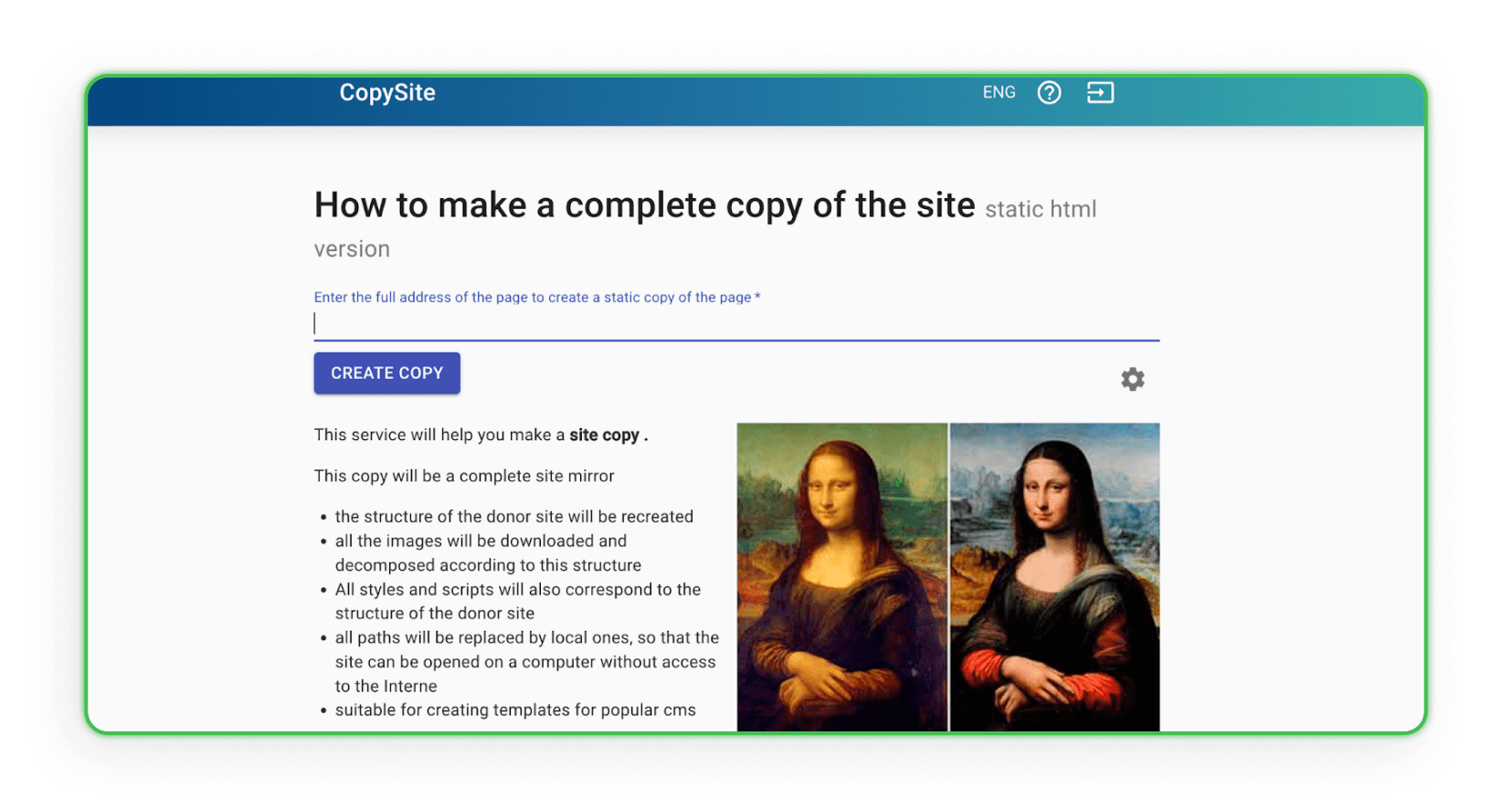
Il sito Xdan è anche un sito russo (disponibile in inglese) che offre CopySite, ovvero servizi di web scraping. Questo sito permette di creare una copia locale di una landing page gratuitamente e scegliere di pulire i contatori HTML o sostituire link o domini.
Copysta

Il servizio russo Copyst è uno dei più veloci di questo tipo. Dichiarano che ti contatteranno entro 15 minuti. Il web scraping viene effettuato tramite link e puoi aggiornare il sito web a pagamento.
Ho scaricato il sito web. E ora?
Hai già scaricato un sito web? Ottimo, ora devi pensare a cosa vuoi farne. Sicuramente vorrai modificarlo un po'. Come?
Come ridisegnare la pagina copiata?
Per ridisegnare la pagina copiata secondo le tue esigenze, devi duplicare la risorsa come preferisci. Per apportare modifiche alla struttura, puoi utilizzare qualsiasi editor che ti consenta di lavorare con il codice, come Visual Studio Code, Notepad ++ (Windows), TextEdit (MacOS), o Sublime Text. Apri un editor che ti è comodo, personalizza il codice, salva e guarda come vengono visualizzate le modifiche nel browser. Modifica l'aspetto visivo dei tag HTML usando il CSS, aggiungi moduli web, pulsanti di azione, link, ecc. Dopo il salvataggio, il file modificato rimarrà sul computer con funzioni aggiornate, layout e azioni mirate.
Alcuni siti raccolgono e analizzano tutti i dati di design da specifici archivi web che dispongono di un sistema di creazione e gestione dei siti web (CMS). Il sistema duplica il progetto con l'amministratore e lo spazio su disco. Archivarix è un esempio di tale sito (il programma può ripristinare e archiviare il progetto).
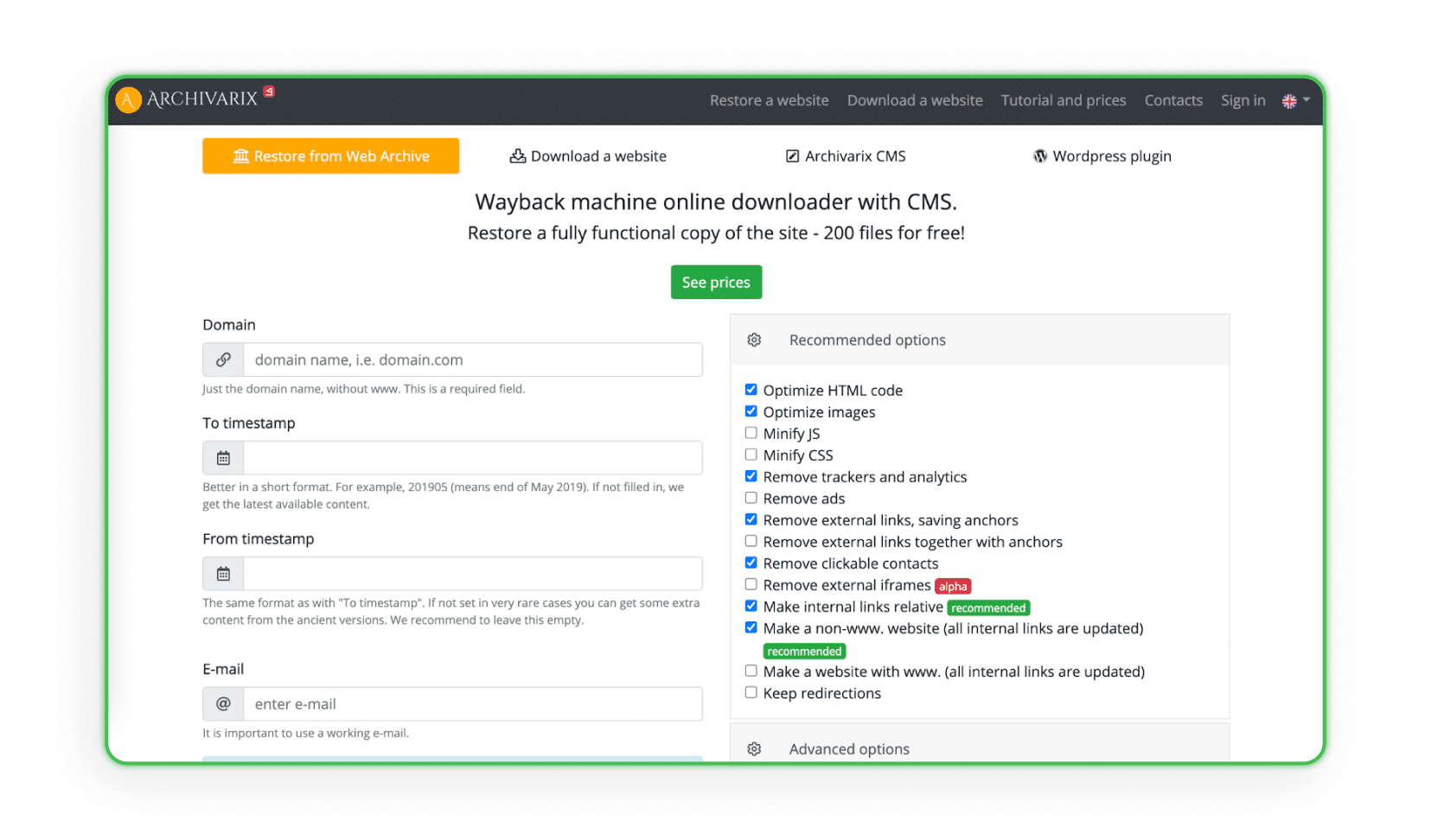
Caricamento dei siti web sull'hosting
L'ultimo e più importante passo nel web scraping delle landing page è caricarle sul tuo hosting. Ricorda che copiare e apportare piccole modifiche visive non è sufficiente. I link di affiliazione di altri, script, pixel di sostituzione, codici JS Metrica e altri contatori rimangono quasi sempre nel codice della pagina. Devono essere rimossi manualmente (o con programmi a pagamento) prima di caricare sul tuo hosting. Se vuoi sapere esattamente come caricare il tuo sito web sull'hosting, consulta il nostro articolo: “Come creare una landing page? Creare un sito passo dopo passo”.
Come difendersi dal web scraping?
La protezione contro il web scraping è essenziale per mantenere la privacy e la sicurezza del tuo sito web e dei suoi dati. Puoi applicare diversi metodi efficaci per ridurre al minimo il rischio di attacchi di web scraping.
• Robots.txt - L'utilizzo del file robots.txt è un modo standard per comunicare con i robot di ricerca. Puoi specificare quali parti del tuo sito devono essere indicizzate e quali no. Sebbene i bot onesti di solito seguano queste linee guida, vale la pena notare che questo file non garantisce protezione contro tutti i bot di scraping.
• .htaccess - Tramite il file .htaccess, puoi bloccare l'accesso per specifici User Agent che i bot possono utilizzare. È un modo per impedire ai bot indesiderati di accedere al tuo sito web./li>
• CSRF (Cross-Site Request Forgery) - Il meccanismo CSRF può proteggere moduli e interazioni con il tuo sito da scraping automatico. Questo può comportare l'uso di token CSRF nei moduli./li>
• Filtraggio degli indirizzi IP - Puoi limitare l'accesso al tuo sito web solo a determinati indirizzi IP, il che può aiutare a ridurre al minimo gli attacchi di web scraping.
• CAPTCHA - L'aggiunta di CAPTCHA a moduli e interazioni può rendere difficile ai bot interagire automaticamente con il tuo sito. È una delle difese più popolari contro lo scraping automatico./li>
• Rate Limiting con mod_qos su server Apache - Impostare limiti per il numero di richieste da un singolo indirizzo IP in un determinato periodo può limitare la possibilità di scaricare automaticamente grandi quantità di dati in poco tempo./li>
• Scrapshield - Il servizio Scrapshield offerto da CloudFlare è uno strumento avanzato per rilevare e bloccare le azioni di web scraping, che può aiutare a proteggere il tuo sito./li>
Se hai mai notato che la tua landing page è stata vittima di tecniche di web scraping, c'è un modo per reindirizzare parte del traffico nuovamente sulla tua pagina.
Sul forum Afflift, troverai un semplice codice JavaScript. Inseriscilo nella tua pagina e ti proteggerà dalla perdita totale di traffico in caso di web scraping.
Il codice si trova in QUESTA DISCUSSIONE.
Felici di vederti qui!
Speriamo che ora tu sappia cos'è il web scraping, come scaricare una pagina web e, soprattutto, come rispettare le leggi sul copyright. Ora tocca a te fare la tua mossa e iniziare a guadagnare. Tuttavia, se hai domande sul marketing di affiliazione o hai bisogno di sapere quale programma scegliere, contattaci.
Hai domande? Non esitare a contattarci tramite i nostri canali.